Discussion Youtube News & Videos
Discussion Articles

Unveiling a Language Model's Biology: Insights into Addition and Medical Diagnosis
Yannic Kilcher explores Anthropics' analysis of a large language model's biology using attribution graphs. The study delves into the model's unique approach to addition and its implications for understanding the model's decision-making process in medical contexts.

Decoding Large Language Models: Anthropic's Transformer Circuit Exploration
Anthropic explores the biology of large language models through transformer circuits, using circuit tracing and transcoders for interpretability. Learn how these models make decisions and handle tasks like poetry without explicit programming.
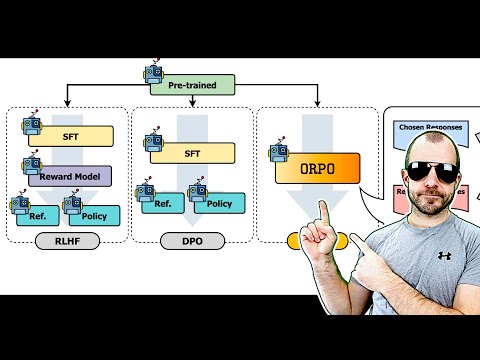
Revolutionizing AI Alignment: Orpo Method Unveiled
Explore Orpo, a groundbreaking AI optimization method aligning language models with instructions without a reference model. Streamlined and efficient, Orpo integrates supervised fine-tuning and odds ratio loss for improved model performance and user satisfaction. Experience the future of AI alignment today.

Tech Roundup: Meta's Chip, Google's Robots, Apple's AI Deal, OpenAI Leak, and More!
Meta unveils powerful new chip; Google DeepMind introduces low-cost robots; Apple signs $50M deal for AI training images; OpenAI researchers embroiled in leak scandal; Adobe trains AI on Mid Journey images; Canada invests $2.4B in AI; Google releases cutting-edge models; Hugging Face introduces iFix 2 Vision language model; Microsoft debuts Row one model; Apple pioneers Faret UI language model for mobile screens.

Unveiling OpenAI's GPT-4: Controversies, Departures, and Industry Shifts
Explore the latest developments with OpenAI's GPT-4 Omni model, its controversies, and the departure of key figures like Ilia Sver and Yan Le. Delve into the balance between AI innovation and commercialization in this insightful analysis by Yannic Kilcher.
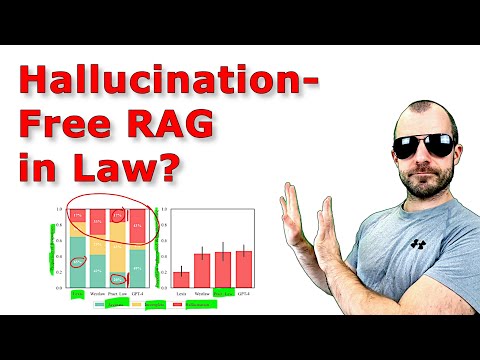
AI Legal Research Tools: Hallucination Study & RAG Impact
Discover the reliability of AI legal research tools in a study by Stanford and Yale researchers. Learn about "hallucinations" in language models and the effectiveness of retrieval augmented generation (RAG) in improving accuracy. Yannic Kilcher shares insights on the integration of AI in legal tech.

Revolutionizing Language Modeling: Efficient Tary Operations Unveiled
Explore how researchers from UC Santa Cruz, UC Davis, and Loxy Tech are revolutionizing language modeling by replacing matrix multiplications with efficient tary operations. Discover the potential efficiency gains and challenges faced in this cutting-edge approach.
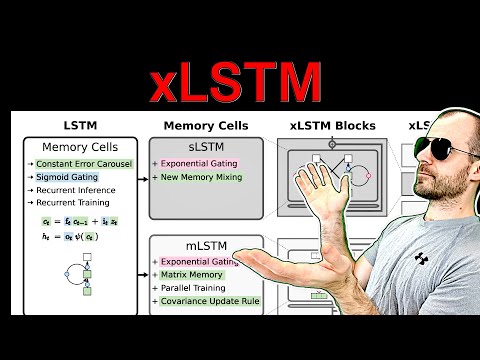
Unleashing XLSTM: Revolutionizing Language Modeling with Innovative Features
Explore XLSTM, a groundbreaking extension of LSTM for language modeling. Learn about its innovative features, comparisons with Transformer models, and experiments driving the future of recurrent architectures.

Unveiling Data Privacy Risks: Manipulating Pre-Trained Models for Data Theft
Explore a groundbreaking paper by Shan L. and Florian Traumer from ETH Zurich, revealing how pre-trained models like Bert can be manipulated to steal sensitive data. Learn about the implications for data privacy and the potential threats posed by blackbox attacks in machine learning models.
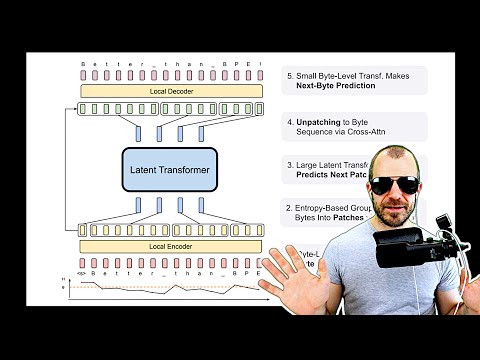
Bite Latent Transformer: Revolutionizing Language Modeling with Dynamic Patch-Based Text Splitting
Discover the groundbreaking Bite Latent Transformer, a revolutionary model that outperforms traditional token-based systems by utilizing dynamic patch-based text splitting. Learn how this innovative approach enhances scaling properties and transforms language modeling.

Enhancing Safety Alignment in Large Language Models: Beyond Initial Tokens
Yannic Kilcher explores enhancing safety alignment in large language models to thwart attacks like jailbreaks by extending alignment beyond initial tokens.

Optimizing Test Time Compute for Large Language Models: Google Deep Mind Collaboration
Yannic Kilcher explores optimizing test time compute for large language models in collaboration with Google Deep Mind and UC Berkeley. Techniques like Chain of Thought prompting and sampling multiple answers are used to enhance model performance on tasks like solving high school math problems. The researchers emphasize thorough experimentation and reporting of results, although generalizing findings to other domains may be challenging. The study requires a verifier model to assess answer correctness and a model for answer refinement, essential for multi-step problem-solving approaches. The researchers propose a taxonomy for modifying model distributions at test time, either at the input or output level. They aim to determine the optimal allocation of test time compute resources for maximal performance benefits on a given prompt. Various strategies like beam search and look-ahead search are explored to refine model outputs iteratively. The paper includes mathematical formalizations, although their practical application in the research is limited. The focus is on practical methods like beam search, scoring multiple answers, and iterative refinement to enhance model performance within given compute constraints.

Revolutionizing AI Scaling: Token Forer Transformer Modification
Discover Token Forer, a groundbreaking modification of Transformer architecture treating model parameters as tokens. Enhancing flexibility in scaling, this approach allows seamless addition of parameters to trained models without starting from scratch.
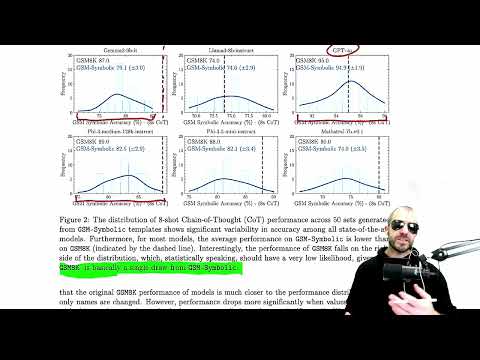
Unveiling AI's Reasoning: GSM Symbolic Data Set Challenges Pattern Matching
Yannic Kilcher explores the limitations of mathematical reasoning in large language models, introducing the GSM symbolic data set to address training set poisoning. The study questions if llms truly reason or rely on pattern matching, sparking debate in the AI research community.
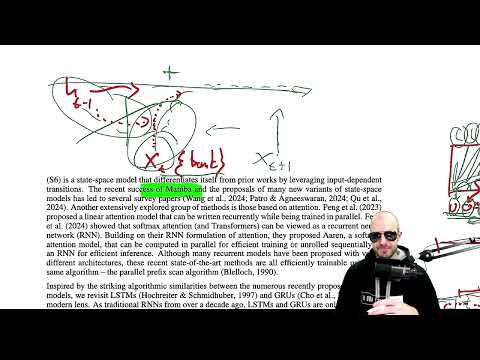
Unveiling the Min GRU: Streamlining RNN Computations for Efficient Processing
Discover the debate on RNN models like S4 and Mamba vs. plain RNNs. Learn how the Min GRU simplifies computations for efficient parallel processing, offering a streamlined alternative. Explore the performance benefits and efficiency of Min GRU compared to traditional models.

AI Insights and Minecraft Adventures: Yannic Kilcher Livestream Highlights
Yannic Kilcher navigates AI benchmarks, test time compute, and verifier accuracy in a lively livestream. Insights on AI's mainstream impact and the quest for AGI are shared amidst Minecraft gameplay.

Unveiling Deep Seek Math: Grpo Approach and 7 Billion Parameter Model
Explore Deep seek math's innovative grpo approach in mathematical reasoning. Learn how their 7 billion parameter model outshines commercial APIs, fueled by a massive dataset from the internet. Witness their journey to mathematical supremacy through meticulous data collection and iterative model training.