Revolutionizing AI Scaling: Token Forer Transformer Modification

- Authors
- Published on
- Published on
Today, we delve into the world of cutting-edge AI with Yannic Kilcher's review of "Token Forer: Rethinking Transformer scaling with tokenized model parameters." Developed by a powerhouse collaboration between MOX Plunk Institute for Informatics, Google, and Peking University, this paper introduces Token Forer, a bold modification of the Transformer architecture. By treating model parameters as tokens, this new approach promises a revolutionary level of flexibility in scaling, allowing for the addition of parameters to a trained model without the need to start from scratch. It's like adding nitrous to a finely-tuned engine without having to rebuild it from the ground up.
Traditionally, Transformers have been shackled by fixed parameters in linear projections, forcing a complete retraining of the model for any modifications. Token Forer changes the game by leveraging attention mechanisms not just for token interactions, but also for interactions between tokens and model parameters. This shift from linear interactions to attention mechanisms opens up a world of possibilities, enabling the seamless integration of additional parameters without the hassle of altering model dimensions. It's like upgrading your car's engine without having to change the entire chassis.
However, as Yannic Kilcher dives deeper into the paper, he uncovers some discrepancies that raise eyebrows. The claimed performance improvements of Token Forer compared to traditional Transformers come into question, especially when analyzing the training data sizes. The team's findings reveal that even at the smallest level, Token Forer seems to outperform traditional methods, sparking skepticism about the validity of the results. It's like claiming your souped-up sports car is faster than a Formula 1 car, but the numbers don't quite add up.

Image copyright Youtube

Image copyright Youtube
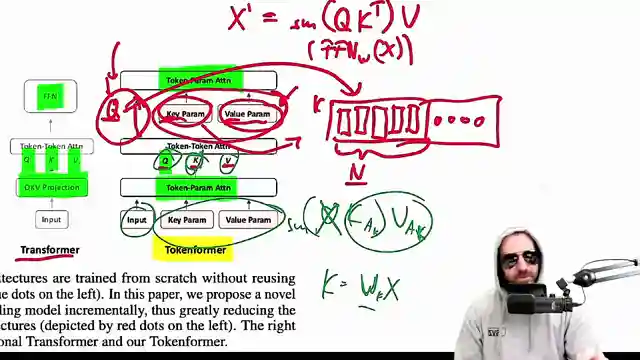
Image copyright Youtube
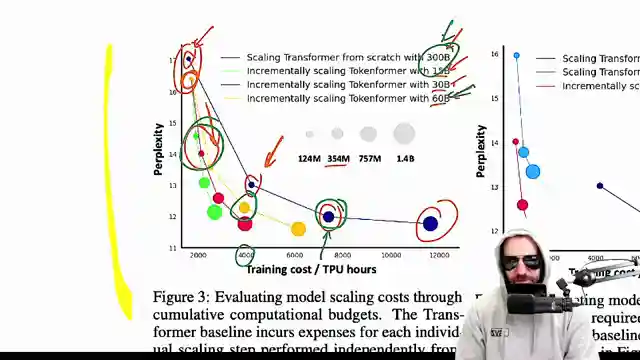
Image copyright Youtube
Watch TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters (Paper Explained) on Youtube
Viewer Reactions for TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters (Paper Explained)
The 757M model is worse but takes less than half the compute to train due to upscaling from smaller models.
The idea of swapping out tokenized parameters based on the input is interesting for creating a kind of memory.
The video was entertaining and structured like a stand-up joke.
The paper focuses on hours to train, not just the number of tokens.
The stability-plasticity dilemma in machine learning should be highlighted more in papers.
The comparison between training a large model from scratch and scaling from a small model over training epochs is requested.
Models tend to compensate in the long run regardless of how they are trained.
Exploring deeper recursion with little sub-transformers in transformers is suggested.
The "pattention" is equivalent to a MLP, surprising some ML researchers.
The QKV projection is generated using another attention mechanism, and there are thoughts on integrating curriculum learning.
Related Articles

Decoding Large Language Models: Anthropic's Transformer Circuit Exploration
Anthropic explores the biology of large language models through transformer circuits, using circuit tracing and transcoders for interpretability. Learn how these models make decisions and handle tasks like poetry without explicit programming.
Revolutionizing AI Alignment: Orpo Method Unveiled
Explore Orpo, a groundbreaking AI optimization method aligning language models with instructions without a reference model. Streamlined and efficient, Orpo integrates supervised fine-tuning and odds ratio loss for improved model performance and user satisfaction. Experience the future of AI alignment today.

Tech Roundup: Meta's Chip, Google's Robots, Apple's AI Deal, OpenAI Leak, and More!
Meta unveils powerful new chip; Google DeepMind introduces low-cost robots; Apple signs $50M deal for AI training images; OpenAI researchers embroiled in leak scandal; Adobe trains AI on Mid Journey images; Canada invests $2.4B in AI; Google releases cutting-edge models; Hugging Face introduces iFix 2 Vision language model; Microsoft debuts Row one model; Apple pioneers Faret UI language model for mobile screens.

Unveiling OpenAI's GPT-4: Controversies, Departures, and Industry Shifts
Explore the latest developments with OpenAI's GPT-4 Omni model, its controversies, and the departure of key figures like Ilia Sver and Yan Le. Delve into the balance between AI innovation and commercialization in this insightful analysis by Yannic Kilcher.