Bite Latent Transformer: Revolutionizing Language Modeling with Dynamic Patch-Based Text Splitting
- Authors
- Published on
- Published on
In this thrilling exploration of cutting-edge technology, the Yannic Kilcher channel delves into the revolutionary Bite Latent Transformer. Forget everything you thought you knew about token-based models because this new approach blows them out of the water. By ditching traditional tokenization in favor of dynamic patch-based text splitting, the Bite Latent Transformer showcases superior scaling capabilities. It's like swapping your trusty old sedan for a sleek, high-performance sports car - the difference is staggering.
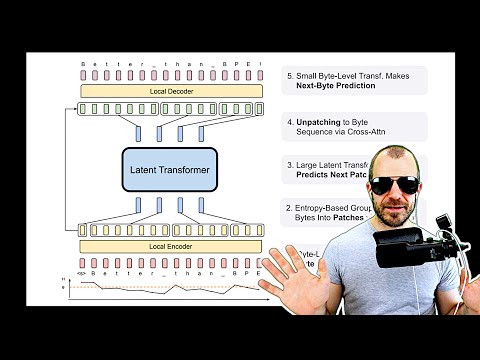
The Bite Latent Transformer operates on patches instead of tokens, a game-changer that propels it ahead of classic models like Byte Pair Encoding. With inner layers running less frequently than outer layers, this Transformer allows for the creation of larger, more powerful models without increasing training flops. It's like having a finely-tuned engine that delivers maximum performance with every stride. By predicting the embedding of the next token more accurately through weight tying, this Transformer takes language modeling to a whole new level.
But that's not all - the paper introduces a dynamic tokenization method known as patching, where a local encoder generates patch embeddings from dynamic groupings of characters or bytes. This innovative approach, coupled with the latent Transformer, offers a flexible and efficient way to process text. Imagine driving a high-speed supercar through winding roads, effortlessly adjusting to the terrain for optimal performance. The Bite Latent Transformer is not just a model; it's a technological marvel that promises a brighter future for language processing.

Image copyright Youtube

Image copyright Youtube
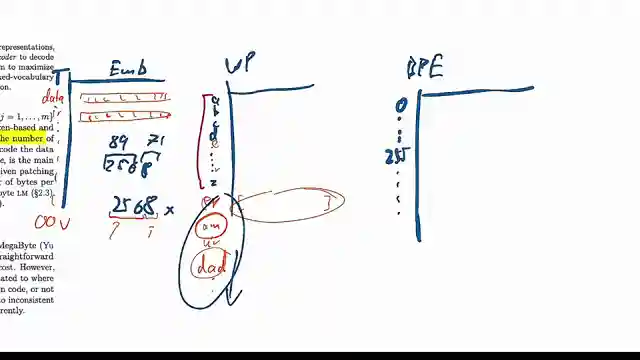
Image copyright Youtube

Image copyright Youtube
Watch Byte Latent Transformer: Patches Scale Better Than Tokens (Paper Explained) on Youtube
Viewer Reactions for Byte Latent Transformer: Patches Scale Better Than Tokens (Paper Explained)
Introduction and abstract of the article
Comparison of scaling properties between BLT, LLaMA 2, and LLaMA 3
Architecture of Byte Latent Transformer
Tokenization and byte-pair encoding explained
Problems with tokenization discussed
Patch embeddings and dynamic tokenization
Entropy-based grouping of bytes into patches
Local encoder and local decoder explained
BLT-specific hyperparameters like patch sizes
Comparison with LLaMA architectures
Related Articles

Decoding Large Language Models: Anthropic's Transformer Circuit Exploration
Anthropic explores the biology of large language models through transformer circuits, using circuit tracing and transcoders for interpretability. Learn how these models make decisions and handle tasks like poetry without explicit programming.
Revolutionizing AI Alignment: Orpo Method Unveiled
Explore Orpo, a groundbreaking AI optimization method aligning language models with instructions without a reference model. Streamlined and efficient, Orpo integrates supervised fine-tuning and odds ratio loss for improved model performance and user satisfaction. Experience the future of AI alignment today.

Tech Roundup: Meta's Chip, Google's Robots, Apple's AI Deal, OpenAI Leak, and More!
Meta unveils powerful new chip; Google DeepMind introduces low-cost robots; Apple signs $50M deal for AI training images; OpenAI researchers embroiled in leak scandal; Adobe trains AI on Mid Journey images; Canada invests $2.4B in AI; Google releases cutting-edge models; Hugging Face introduces iFix 2 Vision language model; Microsoft debuts Row one model; Apple pioneers Faret UI language model for mobile screens.

Unveiling OpenAI's GPT-4: Controversies, Departures, and Industry Shifts
Explore the latest developments with OpenAI's GPT-4 Omni model, its controversies, and the departure of key figures like Ilia Sver and Yan Le. Delve into the balance between AI innovation and commercialization in this insightful analysis by Yannic Kilcher.