Optimizing Test Time Compute for Large Language Models: Google Deep Mind Collaboration

- Authors
- Published on
- Published on
In this riveting analysis by Yannic Kilcher, we delve into a groundbreaking paper from the powerhouses at Google Deep Mind and UC Berkeley. They're on a mission to crack the code on optimizing test time compute for those behemoth language models. It's like fine-tuning a hypercar for the ultimate performance on the track, but instead of horsepower, we're talking about computational muscle. They're not just tinkering under the hood; they're revolutionizing how these models tackle complex tasks, like solving high school math problems. It's like taking a sleek supercar and transforming it into a precision tool for surgical tasks.
The team isn't just theorizing; they're rolling up their sleeves and getting their hands dirty with real-world experiments. They're not content with just scratching the surface; they're diving deep into the nitty-gritty details, leaving no stone unturned. It's like watching a team of engineers dissect every component of a race car to shave off those crucial milliseconds on the track. And let me tell you, the results are nothing short of jaw-dropping. They're not just aiming for good; they're gunning for greatness, pushing the boundaries of what these models can achieve.
But it's not all smooth sailing; there are challenges along the way. They're not just cruising down an open road; they're navigating treacherous terrain, facing obstacles at every turn. It's like a high-speed race with unexpected twists and turns, testing the limits of their expertise. Yet, they press on, undeterred by the hurdles, fueled by the passion to unlock the full potential of these language models. And as we witness this thrilling journey unfold, one thing becomes abundantly clear - the future of AI is in good hands with these trailblazers at the helm.

Image copyright Youtube

Image copyright Youtube
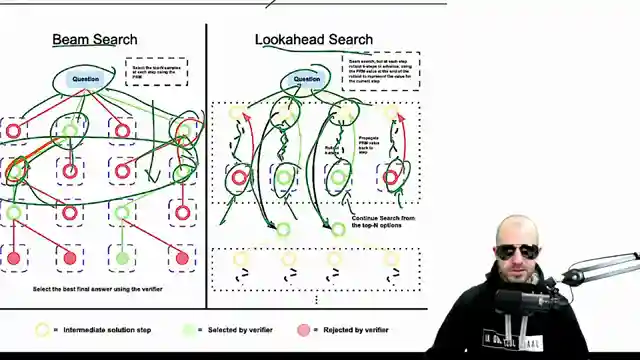
Image copyright Youtube
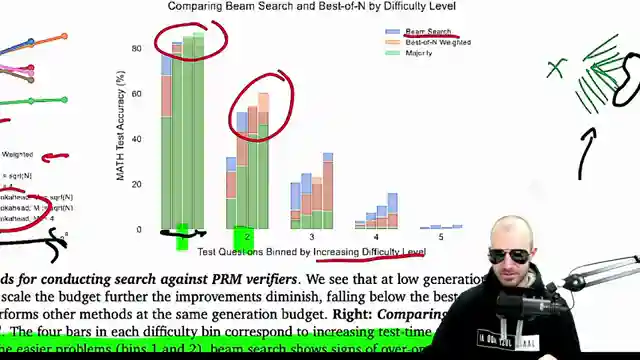
Image copyright Youtube
Watch Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters (Paper) on Youtube
Viewer Reactions for Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters (Paper)
Discussion on the paper's content and methodology
Appreciation for the breakdown of the paper
Excitement for the return of the content creator
Reference to related works and scaling laws for inference
Comments on the absence of certain elements in the paper, like error bars
Questions and discussions on the optimization process and ground truth
Observations on the correlation between question difficulty and accuracy
Calls for open-sourcing certain tools and models
Praise for the content creator and their explanations
Comments on the success and relevance of the discussed idea
Related Articles

Decoding Large Language Models: Anthropic's Transformer Circuit Exploration
Anthropic explores the biology of large language models through transformer circuits, using circuit tracing and transcoders for interpretability. Learn how these models make decisions and handle tasks like poetry without explicit programming.
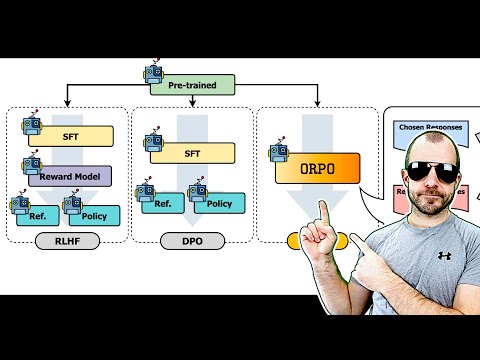
Revolutionizing AI Alignment: Orpo Method Unveiled
Explore Orpo, a groundbreaking AI optimization method aligning language models with instructions without a reference model. Streamlined and efficient, Orpo integrates supervised fine-tuning and odds ratio loss for improved model performance and user satisfaction. Experience the future of AI alignment today.

Tech Roundup: Meta's Chip, Google's Robots, Apple's AI Deal, OpenAI Leak, and More!
Meta unveils powerful new chip; Google DeepMind introduces low-cost robots; Apple signs $50M deal for AI training images; OpenAI researchers embroiled in leak scandal; Adobe trains AI on Mid Journey images; Canada invests $2.4B in AI; Google releases cutting-edge models; Hugging Face introduces iFix 2 Vision language model; Microsoft debuts Row one model; Apple pioneers Faret UI language model for mobile screens.

Unveiling OpenAI's GPT-4: Controversies, Departures, and Industry Shifts
Explore the latest developments with OpenAI's GPT-4 Omni model, its controversies, and the departure of key figures like Ilia Sver and Yan Le. Delve into the balance between AI innovation and commercialization in this insightful analysis by Yannic Kilcher.