Unveiling the Min GRU: Streamlining RNN Computations for Efficient Processing
- Authors
- Published on
- Published on
In this riveting analysis, the Yannic Kilcher team dives headfirst into the roaring debate surrounding the necessity of modern RNN-style models like S4 and Mamba. They boldly question the very essence of these complex constructs, suggesting that perhaps a good old plain RNN might just do the trick if handled correctly. It's a bit like pitting a classic muscle car against the latest flashy supercar - can raw power and simplicity outshine the bells and whistles of modern technology?
The team takes us on a thrilling ride through the treacherous terrain of Transformer models versus RNNs, highlighting the inherent limitations of Transformers due to their attention mechanism's memory requirements. While Transformers struggle with sequence length, RNNs emerge as the rugged off-roaders of the neural network world, effortlessly handling sequences of any length. But it's not all smooth sailing for RNNs, as they grapple with challenges like backpropagation through time and input dependencies that have plagued traditional models like LSTMs and GRUs.
Enter the Min GRU - a stripped-down, no-nonsense RNN cell that kicks complexity to the curb and embraces parallel computation with open arms. By cutting ties with past hidden state influences, the Min GRU revs up efficiency and speed, introducing a parallel scan algorithm that turbocharges sequential data processing. This sleek and simplified design ensures that the next hidden state is solely determined by the current input, shedding the shackles of past dependencies and paving the way for lightning-fast computations. As the team compares the performance metrics of Min GRU, LSTMs, and GRUs, it becomes clear that the Min GRU's constant training runtime and memory efficiency make it a true contender in the neural network arena.

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube
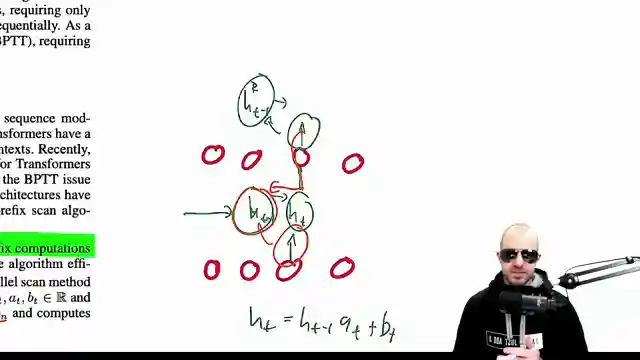
Image copyright Youtube
Watch Were RNNs All We Needed? (Paper Explained) on Youtube
Viewer Reactions for Were RNNs All We Needed? (Paper Explained)
Excitement about the potential impact of the paper if released earlier
Comparison between RNNs and Transformers in terms of memory requirements and limitations
Introduction of minimal versions of GRUs and LSTMs
Discussion on the trade-offs between simpler RNNs and traditional RNNs
Experimental results on tasks like selective copying, reinforcement learning benchmarks, and language modeling
Mention of the potential for scalability and efficiency of minimal RNNs
Comments on the need for further research and experimentation with ensembles of minGRUs
Discussion on the power of transformers and their training efficiency
Questions about the choice of benchmarks and comparisons in the paper
Suggestions for future research topics like the architecture of the liquid foundation model
Related Articles

Decoding Large Language Models: Anthropic's Transformer Circuit Exploration
Anthropic explores the biology of large language models through transformer circuits, using circuit tracing and transcoders for interpretability. Learn how these models make decisions and handle tasks like poetry without explicit programming.
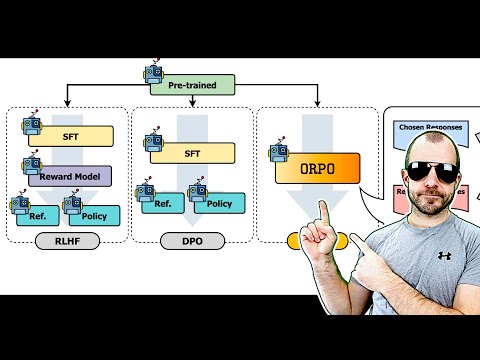
Revolutionizing AI Alignment: Orpo Method Unveiled
Explore Orpo, a groundbreaking AI optimization method aligning language models with instructions without a reference model. Streamlined and efficient, Orpo integrates supervised fine-tuning and odds ratio loss for improved model performance and user satisfaction. Experience the future of AI alignment today.

Tech Roundup: Meta's Chip, Google's Robots, Apple's AI Deal, OpenAI Leak, and More!
Meta unveils powerful new chip; Google DeepMind introduces low-cost robots; Apple signs $50M deal for AI training images; OpenAI researchers embroiled in leak scandal; Adobe trains AI on Mid Journey images; Canada invests $2.4B in AI; Google releases cutting-edge models; Hugging Face introduces iFix 2 Vision language model; Microsoft debuts Row one model; Apple pioneers Faret UI language model for mobile screens.

Unveiling OpenAI's GPT-4: Controversies, Departures, and Industry Shifts
Explore the latest developments with OpenAI's GPT-4 Omni model, its controversies, and the departure of key figures like Ilia Sver and Yan Le. Delve into the balance between AI innovation and commercialization in this insightful analysis by Yannic Kilcher.