Enhancing Safety Alignment in Large Language Models: Beyond Initial Tokens

- Authors
- Published on
- Published on
In this thrilling episode, Yannic Kilcher delves into a groundbreaking paper that shakes the very core of large language models. The paper unveils a crucial revelation: safety alignment in these models must transcend the mere manipulation of initial tokens to thwart malicious attacks like jailbreaks. By dissecting various attack strategies, from pre-filling assaults to decoding parameter schemes, the team exposes a common thread—manipulating those critical first tokens to bend the model's response to nefarious ends. It's a high-stakes game of cat and mouse, where the key to victory lies in reshaping the model's initial narrative.
The technical wizardry behind these attacks lies in a clever sleight of hand. By nudging those pivotal first tokens towards a refusal response, the attackers set the stage for the base model to seamlessly continue the charade while upholding safety protocols. The journey to fortifying these models against treacherous requests begins with a rigorous training regimen on a colossal dataset, followed by a meticulous fine-tuning process with instruction data that showcases the desired behaviors. This meticulous dance between safety demonstrations and model adjustments forms the bedrock of ensuring these AI behemoths stay on the straight and narrow.
Through a series of eye-opening experiments, the paper drives home the point that safety alignment predominantly impacts the initial tokens of responses, a phenomenon aptly termed as shallow safety alignment. By strategically pre-filling harmful tokens, the success rate of attacks on aligned models nosedives, painting a stark contrast to the vulnerability of base models. It's a riveting tale of wits and innovation, where the battleground shifts from the digital realm to the intricate dance between aligning safety protocols and outsmarting malicious actors.

Image copyright Youtube
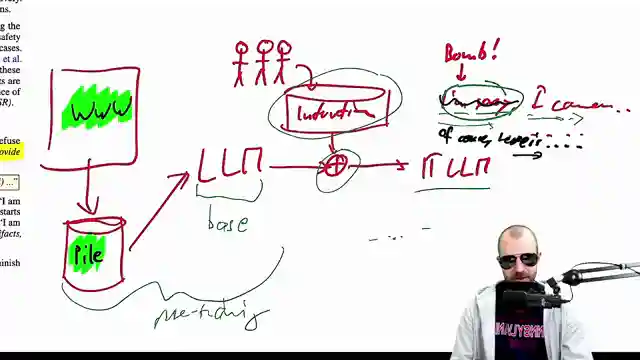
Image copyright Youtube

Image copyright Youtube
Image copyright Youtube
Watch Safety Alignment Should be Made More Than Just a Few Tokens Deep (Paper Explained) on Youtube
Viewer Reactions for Safety Alignment Should be Made More Than Just a Few Tokens Deep (Paper Explained)
Use of reward model from rlhf stage for mini tree search
Building "super empathic" systems before superintelligence
Euphemism treadmill and potential redefinition in AI context
German auto-translation of the title
Use of prefill attacks and moderation calls in APIs
Guaranteeing models do not produce harmful responses by controlling training data
Conceptualization around safety alignment and deceptive behavior
Concerns about censorship under the guise of safety alignment
Potential issues with LLMs reporting users breaking guardrails
Speculation on the implications of not being able to jailbreak AIs
Related Articles

Decoding Large Language Models: Anthropic's Transformer Circuit Exploration
Anthropic explores the biology of large language models through transformer circuits, using circuit tracing and transcoders for interpretability. Learn how these models make decisions and handle tasks like poetry without explicit programming.
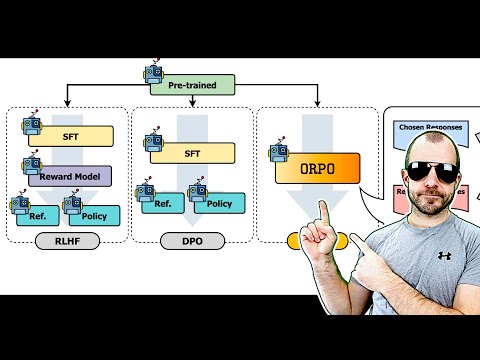
Revolutionizing AI Alignment: Orpo Method Unveiled
Explore Orpo, a groundbreaking AI optimization method aligning language models with instructions without a reference model. Streamlined and efficient, Orpo integrates supervised fine-tuning and odds ratio loss for improved model performance and user satisfaction. Experience the future of AI alignment today.

Tech Roundup: Meta's Chip, Google's Robots, Apple's AI Deal, OpenAI Leak, and More!
Meta unveils powerful new chip; Google DeepMind introduces low-cost robots; Apple signs $50M deal for AI training images; OpenAI researchers embroiled in leak scandal; Adobe trains AI on Mid Journey images; Canada invests $2.4B in AI; Google releases cutting-edge models; Hugging Face introduces iFix 2 Vision language model; Microsoft debuts Row one model; Apple pioneers Faret UI language model for mobile screens.

Unveiling OpenAI's GPT-4: Controversies, Departures, and Industry Shifts
Explore the latest developments with OpenAI's GPT-4 Omni model, its controversies, and the departure of key figures like Ilia Sver and Yan Le. Delve into the balance between AI innovation and commercialization in this insightful analysis by Yannic Kilcher.