Mastering BERT: Bird Algorithm, RoBERTa, and SageMaker Processing
- Authors
- Published on
- Published on
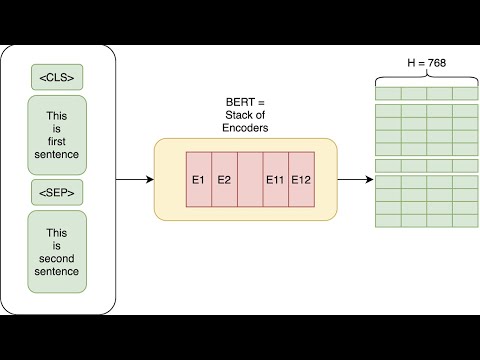
Machine Learning TV delves into the fascinating world of the Bird algorithm, a revolutionary tool that transforms raw product review text into embeddings understood by the powerful Bidirectional Encoder Representations from Transformers (BERT). Contrasting with the traditional BlazingText, BERT operates at a sophisticated sentence level, capturing intricate word context through its cutting-edge Transformer architecture. While BlazingText churns out static embeddings regardless of context, BERT's dynamic embeddings based on token, segment, and position bring a whole new level of depth to the table. Take, for example, the word "dress" in two sentences like "I love the dress" and "I love the dress but not the price" - BERT's embeddings adapt, reflecting the nuanced context of each scenario.
To convert sequences into these groundbreaking BERT embeddings, a meticulous process unfolds involving wordpiece tokenization, token, segment, and position embeddings, resulting in a fixed-length embedding that encapsulates the essence of the input sequence. The channel introduces libraries and APIs like scikit-learn and the RoBERTa tokenizer class, empowering enthusiasts to programmatically generate BERT embeddings from raw text with ease. RoBERTa, a refined iteration of BERT, boasts enhanced performance in various NLP tasks thanks to tweaked hyperparameters and an expanded training dataset. By seamlessly integrating the RoBERTa tokenizer, enthusiasts can tap into the power of pre-trained models like RoBERTa base, setting the stage for a seamless encode plus method execution with critical parameters like the review text and max sequence length.
Scaling up the generation of these game-changing embeddings becomes a reality through the ingenious Amazon SageMaker processing, a tool that enables data-related tasks like feature engineering at an unprecedented scale using distributed clusters. With a built-in container for scikit-learn, SageMaker processing simplifies the process of handling data stored in S3 buckets, executing scripts to generate embeddings and seamlessly storing outputs back in the cloud. The lab for the week promises an exhilarating journey into converting review text into BERT embeddings at scale, leveraging the scikit-learn container on SageMaker processing to unlock a world of possibilities in the realm of machine learning and natural language processing.

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube
Watch Understanding BERT Embeddings and How to Generate them in SageMaker on Youtube
Viewer Reactions for Understanding BERT Embeddings and How to Generate them in SageMaker
Summary: The comment asks if positional encoding is done with a sinusoidal function.
Top comments:
Discussion on the use of sinusoidal function for positional encoding.
Related Articles
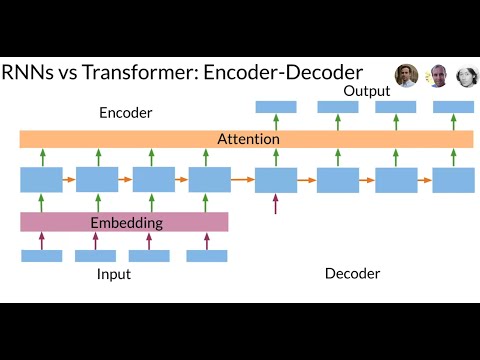
Revolutionizing Neural Networks: The Power of Transformer Models
Discover how the Transformer model revolutionizes neural networks, outperforming RNNs in sequence data processing. Say goodbye to slow computations and vanishing gradients with the Transformer's attention-based approach and multi-head layers. Embrace the future of efficient translation and sequence tasks!

Decoding Time Series Patterns: Trends, Seasonality, and Predictions
Machine Learning TV explores time series patterns like trend, seasonality, and autocorrelation, offering insights into predicting and analyzing data with real-world examples.

Mastering Language Model Evaluation: Perplexity and Text Coherence
Learn how to evaluate language models using perplexity, a key metric measuring text complexity. Split data for training, validation, and testing to assess model performance. Lower perplexity scores indicate more natural language generation. Explore bi-gram and trigram models for enhanced text coherence.

Mastering Vanishing Gradients: LSTM Solutions for RNN Efficiency
Explore how Machine Learning TV tackles the vanishing gradient problem in RNNs using LSTMs. Discover solutions like weight initialization and gradient clipping to optimize training efficiency.