Revolutionizing Neural Networks: The Power of Transformer Models
- Authors
- Published on
- Published on
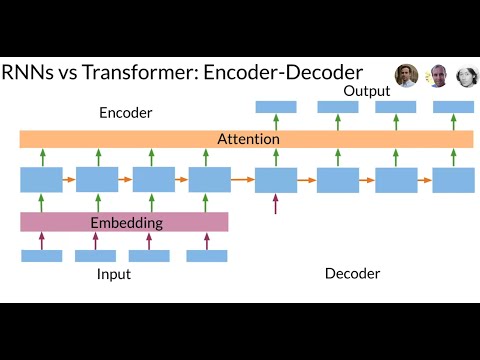
In a world where neural networks reign supreme, a team of brilliant minds at Google has unleashed the mighty Transformer model to crush the limitations of recurrent neural networks. Picture this: you're translating from English to German using an RNN, and you're stuck in a sequential nightmare, processing words one by one like a tortoise on a marathon. But fear not, for the Transformer swoops in with its attention-based magic, requiring just one step per layer, leaving the RNNs in the dust.
Forget about losing vital information and those pesky vanishing gradients haunting your RNN dreams. The Transformer's multi-head attention layers bring the thunder, mimicking the effects of recurrence while maintaining parallel processing prowess. And let's not overlook the positional encoding stage, ensuring that each word in a sequence retains its rightful place in the grand linguistic tapestry. It's like having a symphony of intelligence orchestrating the perfect translation performance.
RNNs, with their sequential shackles, struggle to keep up with the lightning-fast Transformer that dances through computations with grace and efficiency. The Transformer doesn't break a sweat when faced with lengthy sequences, effortlessly capturing the essence of each word's position and order. Say goodbye to the sluggishness of RNNs and embrace the future of sequence data processing with the Transformer. It's a revolution in the world of neural networks, a game-changer that's here to stay.

Image copyright Youtube
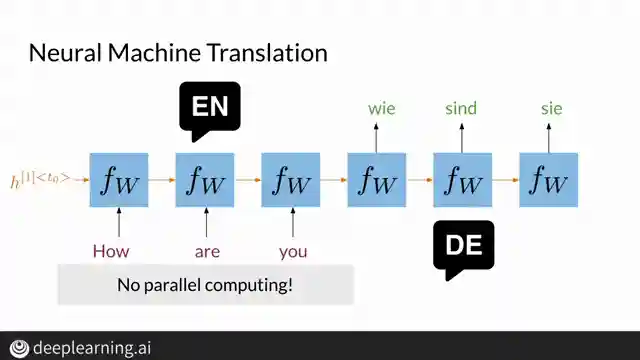
Image copyright Youtube

Image copyright Youtube
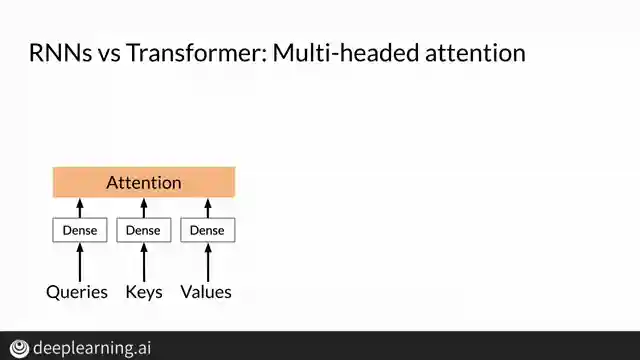
Image copyright Youtube
Watch Transformers vs Recurrent Neural Networks (RNN)! on Youtube
Viewer Reactions for Transformers vs Recurrent Neural Networks (RNN)!
Visuals are very helpful
Request for comparison between RNN and transformer
Specific location mentioned
Issue with anomaly detection classification using RNN in keras.tf, with accuracy and val_accuracy values remaining constant at 50%
Related Articles
Revolutionizing Neural Networks: The Power of Transformer Models
Discover how the Transformer model revolutionizes neural networks, outperforming RNNs in sequence data processing. Say goodbye to slow computations and vanishing gradients with the Transformer's attention-based approach and multi-head layers. Embrace the future of efficient translation and sequence tasks!

Decoding Time Series Patterns: Trends, Seasonality, and Predictions
Machine Learning TV explores time series patterns like trend, seasonality, and autocorrelation, offering insights into predicting and analyzing data with real-world examples.

Mastering Language Model Evaluation: Perplexity and Text Coherence
Learn how to evaluate language models using perplexity, a key metric measuring text complexity. Split data for training, validation, and testing to assess model performance. Lower perplexity scores indicate more natural language generation. Explore bi-gram and trigram models for enhanced text coherence.

Mastering Vanishing Gradients: LSTM Solutions for RNN Efficiency
Explore how Machine Learning TV tackles the vanishing gradient problem in RNNs using LSTMs. Discover solutions like weight initialization and gradient clipping to optimize training efficiency.