Mastering Language Model Evaluation: Perplexity and Text Coherence

- Authors
- Published on
- Published on
In this riveting episode of Machine Learning TV, the team delves into the intricate world of evaluating language models using the enigmatic metric known as perplexity. Perplexity, a measure of text complexity, separates the men from the boys in the realm of natural language processing. By splitting data into distinct sets for training, validation, and testing, you can gauge how well your model performs on fresh, unseen data - a crucial test of its mettle.
Calculating perplexity involves diving deep into the probabilities of sentences within the test set, unraveling the mystery of language generation. The lower the perplexity score, the more human-like the text sounds, indicating a finely-tuned model. From bi-gram to trigram models, the evolution of language coherence becomes apparent, with lower perplexity scores leading to more sensible and natural language output. Researchers often opt for log perplexity for its ease of computation, shedding light on the inner workings of language models.
As the Machine Learning TV crew navigates through the intricacies of language evaluation, they shed light on the significance of handling out-of-vocabulary words in training sets. This critical step ensures that language models can adapt and generate coherent text even when faced with unfamiliar terms. The journey through perplexity and model evaluation sets the stage for real-world language model applications, offering a glimpse into the future of deep learning models with even lower perplexity scores.

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube
Watch Language Model Evaluation and Perplexity on Youtube
Viewer Reactions for Language Model Evaluation and Perplexity
Introduction and outline at 00:00
Splitting the corpus at 00:24
Splitting methods at 01:29
Perplexity metric at 01:53
Perplexity examples at 03:23
Perplexity for bigram models at 04:32
Log perplexity and typical values for log perplexity at 05:16
Texts generated by models with different perplexity at 05:50
Issue with the perplexity formula
Clarification on "normalized by number of words" in perplexity definition
Using perplexity to evaluate GPT2 model for predicting protein sequences
Related Articles
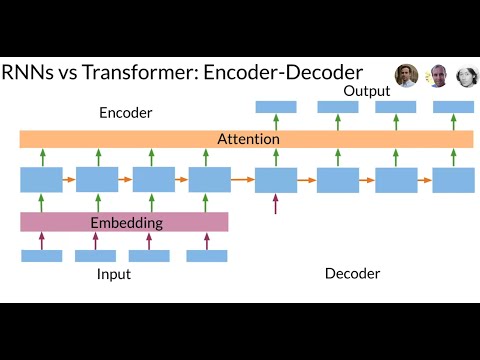
Revolutionizing Neural Networks: The Power of Transformer Models
Discover how the Transformer model revolutionizes neural networks, outperforming RNNs in sequence data processing. Say goodbye to slow computations and vanishing gradients with the Transformer's attention-based approach and multi-head layers. Embrace the future of efficient translation and sequence tasks!

Decoding Time Series Patterns: Trends, Seasonality, and Predictions
Machine Learning TV explores time series patterns like trend, seasonality, and autocorrelation, offering insights into predicting and analyzing data with real-world examples.
Mastering Language Model Evaluation: Perplexity and Text Coherence
Learn how to evaluate language models using perplexity, a key metric measuring text complexity. Split data for training, validation, and testing to assess model performance. Lower perplexity scores indicate more natural language generation. Explore bi-gram and trigram models for enhanced text coherence.

Mastering Vanishing Gradients: LSTM Solutions for RNN Efficiency
Explore how Machine Learning TV tackles the vanishing gradient problem in RNNs using LSTMs. Discover solutions like weight initialization and gradient clipping to optimize training efficiency.