Mastering Kalman Filters: Best Estimation for Self-Driving Cars
- Authors
- Published on
- Published on
In this riveting episode, the Machine Learning TV gang delves into the captivating world of the Kalman filter, unravelling its mystique as a top-notch estimation method. They eloquently dissect the notions of bias and consistency in state estimation, shedding light on their paramount significance. With the precision of a surgeon, they declare the Kalman filter as the crème de la crème of linear unbiased estimators, affectionately known as the BLUE.
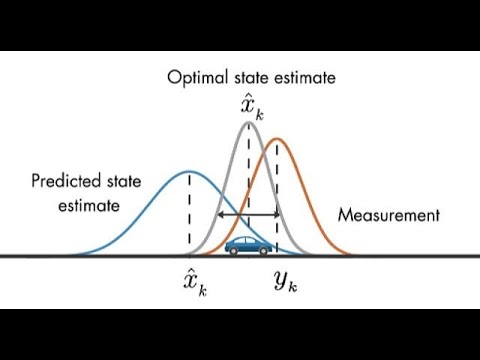
The team embarks on a thrilling journey through the realm of bias, using the Kalman filter to track the position of a futuristic autonomous car. By juxtaposing the filter's estimates with the vehicle's true position, they unveil the essence of unbiasedness through meticulous error analysis. Armed with theoretical prowess, they unveil the prerequisites for unbiasedness, emphasizing the pivotal role of initial state estimates and noise characteristics in achieving this elusive trait.
As the discussion unfolds, the team unveils the concept of consistency in Kalman filters, where the covariance aligns with the expected error square value. They caution against overconfidence in filters, a pitfall that can plunge self-driving cars into perilous waters. With a blend of theoretical insights and practical wisdom, they crown the Kalman filter as the ultimate beacon of unbiasedness and consistency, earning its prestigious title as the best linear unbiased estimator. The stage is set for a thrilling sequel where nonlinear estimation challenges await their expert scrutiny.

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube
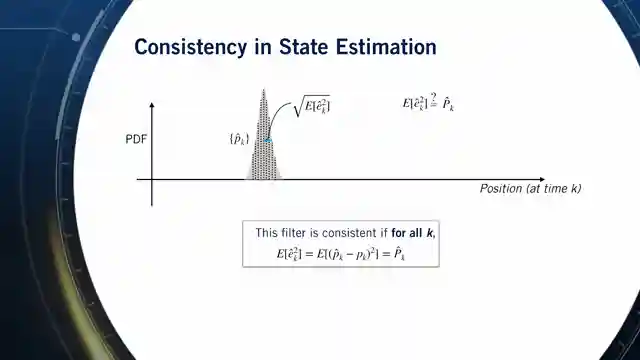
Image copyright Youtube
Watch Kalman Filter - Part 2 on Youtube
Viewer Reactions for Kalman Filter - Part 2
Viewers are interested in follow-up lectures on the topic
Some are specifically asking for a Part 3 on extended Kalman filter
Mention of self-driving rockets
Disappointment expressed over the lack of a Part 3 in the video series
Related Articles
Revolutionizing Neural Networks: The Power of Transformer Models
Discover how the Transformer model revolutionizes neural networks, outperforming RNNs in sequence data processing. Say goodbye to slow computations and vanishing gradients with the Transformer's attention-based approach and multi-head layers. Embrace the future of efficient translation and sequence tasks!

Decoding Time Series Patterns: Trends, Seasonality, and Predictions
Machine Learning TV explores time series patterns like trend, seasonality, and autocorrelation, offering insights into predicting and analyzing data with real-world examples.

Mastering Language Model Evaluation: Perplexity and Text Coherence
Learn how to evaluate language models using perplexity, a key metric measuring text complexity. Split data for training, validation, and testing to assess model performance. Lower perplexity scores indicate more natural language generation. Explore bi-gram and trigram models for enhanced text coherence.

Mastering Vanishing Gradients: LSTM Solutions for RNN Efficiency
Explore how Machine Learning TV tackles the vanishing gradient problem in RNNs using LSTMs. Discover solutions like weight initialization and gradient clipping to optimize training efficiency.