Mastering Vanishing Gradients: LSTM Solutions for RNN Efficiency

- Authors
- Published on
- Published on
In this riveting episode, Machine Learning TV delves into the intricate world of long short-term memory cells (LSTMs) and the notorious vanishing gradient problem plaguing recurrent neural networks (RNNs). RNNs, with their ability to recall past information, struggle with longer sequences due to these pesky vanishing or exploding gradients. As the information traverses through the sequence, the early steps gradually lose their influence on the final output and cost function, creating a tumultuous journey for the network.
Backpropagation, the process of updating weights during training, becomes a treacherous affair in networks with numerous time steps or layers. Gradients, essential for determining how much a model can improve over time, can dwindle to such minuscule values that weight updates are rendered ineffective. Conversely, the nightmare of exploding gradients occurs when updated weights spiral out of control, destabilizing the entire network and risking numerical overflow.
To combat the vanishing gradient menace, the team proposes ingenious solutions such as weight initialization to the identity matrix, employing a ReLU activation function, and implementing gradient clipping to rein in the magnitude of gradients. Furthermore, skip connections offer a lifeline by establishing a direct pathway to earlier layers, empowering initial activations to wield more influence over the cost function. These cutting-edge techniques provide a beacon of hope in the tumultuous realm of RNNs, offering a glimpse into the transformative power of LSTMs in overcoming the challenges posed by vanishing gradients.

Image copyright Youtube

Image copyright Youtube
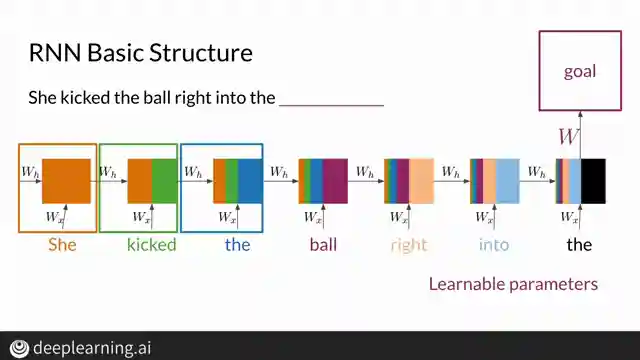
Image copyright Youtube
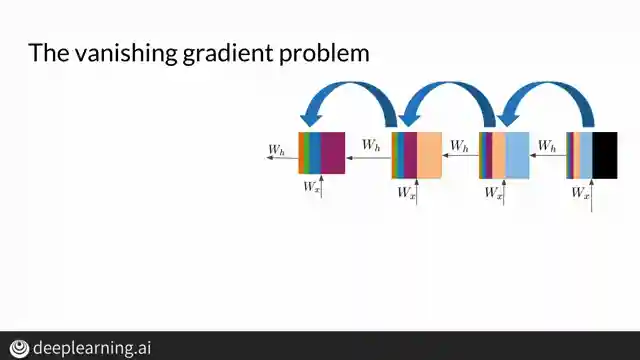
Image copyright Youtube
Watch Recurrent Neural Networks (RNNs) and Vanishing Gradients on Youtube
Viewer Reactions for Recurrent Neural Networks (RNNs) and Vanishing Gradients
I'm sorry, but I need the specific video link or the comments to provide a summary.
Related Articles
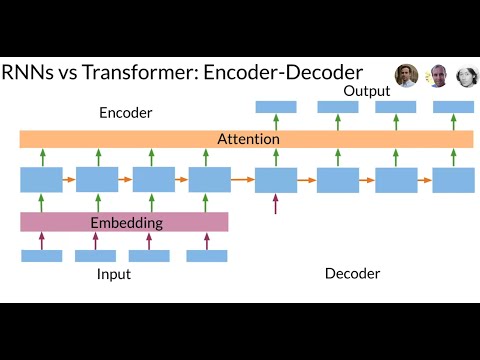
Revolutionizing Neural Networks: The Power of Transformer Models
Discover how the Transformer model revolutionizes neural networks, outperforming RNNs in sequence data processing. Say goodbye to slow computations and vanishing gradients with the Transformer's attention-based approach and multi-head layers. Embrace the future of efficient translation and sequence tasks!

Decoding Time Series Patterns: Trends, Seasonality, and Predictions
Machine Learning TV explores time series patterns like trend, seasonality, and autocorrelation, offering insights into predicting and analyzing data with real-world examples.

Mastering Language Model Evaluation: Perplexity and Text Coherence
Learn how to evaluate language models using perplexity, a key metric measuring text complexity. Split data for training, validation, and testing to assess model performance. Lower perplexity scores indicate more natural language generation. Explore bi-gram and trigram models for enhanced text coherence.
Mastering Vanishing Gradients: LSTM Solutions for RNN Efficiency
Explore how Machine Learning TV tackles the vanishing gradient problem in RNNs using LSTMs. Discover solutions like weight initialization and gradient clipping to optimize training efficiency.