Unveiling the Power of Large Language Models with Princeton NLP Experts
- Authors
- Published on
- Published on
In this thrilling episode, Alexander and Amit, two brilliant minds from the Princeton NLP group, delve into the fascinating world of building large language models from the ground up. These models are the very backbone of the revolutionary Chachi GPT, a technology that would be unimaginable without the groundwork laid by these massive language models. They take us on a journey through tokenization, where words are transformed into numbers, and subword tokenization, a clever method to handle the vast and unpredictable space of words in natural language.
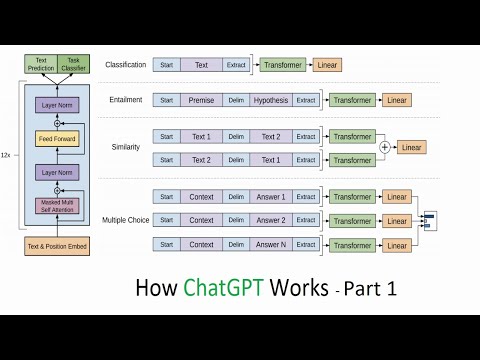
The dynamic duo introduces us to the concept of word embeddings, powerful vectors that allow similar words to be grouped together in a high-dimensional space. These embeddings enable models to learn representations with remarkable characteristics, shaping the way language is understood and processed by machines. As they unravel the mystery behind large language models, they shed light on the transformative Transformer architecture, a neural network design that has revolutionized the field of natural language processing.
Self-attention emerges as a crucial operation within Transformers, facilitating the seamless integration of information from past tokens into current predictions. Meanwhile, the feed-forward layers play a pivotal role in mapping embeddings to predict the next token, storing essential factual knowledge along the way. With each layer in models like GPT3 consisting of about 100 layers, the flexibility and adaptability of these models to handle vast amounts of data and make complex predictions are truly awe-inspiring. Join Alexander and Amit as they unlock the secrets of language modeling and take us on a thrilling ride through the cutting-edge world of NLP.

Image copyright Youtube

Image copyright Youtube
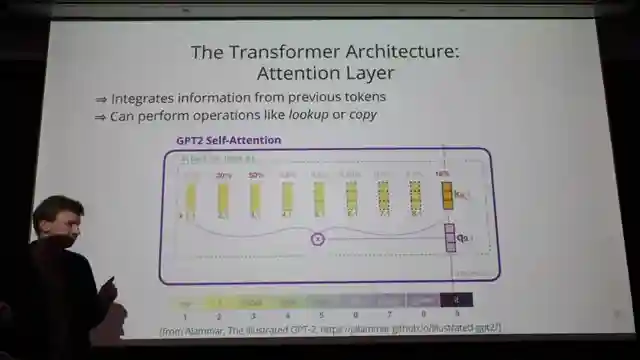
Image copyright Youtube

Image copyright Youtube
Watch Understanding ChatGPT and LLMs from Scratch - Part 1 on Youtube
Viewer Reactions for Understanding ChatGPT and LLMs from Scratch - Part 1
Request for code repository
Token exhaustion issue with GPT4
Speculation about token exhaustion being resolved in GPT5
Related Articles
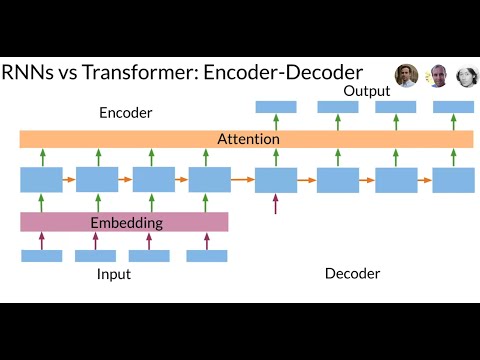
Revolutionizing Neural Networks: The Power of Transformer Models
Discover how the Transformer model revolutionizes neural networks, outperforming RNNs in sequence data processing. Say goodbye to slow computations and vanishing gradients with the Transformer's attention-based approach and multi-head layers. Embrace the future of efficient translation and sequence tasks!

Decoding Time Series Patterns: Trends, Seasonality, and Predictions
Machine Learning TV explores time series patterns like trend, seasonality, and autocorrelation, offering insights into predicting and analyzing data with real-world examples.

Mastering Language Model Evaluation: Perplexity and Text Coherence
Learn how to evaluate language models using perplexity, a key metric measuring text complexity. Split data for training, validation, and testing to assess model performance. Lower perplexity scores indicate more natural language generation. Explore bi-gram and trigram models for enhanced text coherence.

Mastering Vanishing Gradients: LSTM Solutions for RNN Efficiency
Explore how Machine Learning TV tackles the vanishing gradient problem in RNNs using LSTMs. Discover solutions like weight initialization and gradient clipping to optimize training efficiency.