Revolutionizing AI: Super Hot Extends Context Length to 32k Tokens

- Authors
- Published on
- Published on
In this riveting discussion by AemonAlgiz, the team delves into the complexities of extending context length in cutting-edge models like Super Hot. They tackle the challenges posed by the quadratic complexity of the attention layer and the limitations of extrapolation in positional encoding. The comparison between soft max and ReLU sheds light on neuron activation differences, crucial for understanding model behavior. Previous techniques such as Alibi and landmark are scrutinized for their shortcomings in extending context, with Alibi's bias towards later tokens highlighted as a drawback.
The exploration of positional encoding nuances reveals the shortcomings of sinusoidal encoding, prompting the development of Rotary encodings to enhance positionality information. Innovative methods like random positional encoding and shifted positional encoding are discussed as attempts to boost context length, with log n scaling also thrown into the mix for consideration. The concept of Rotary encodings emerges as a game-changer, offering a unique approach to embedding positional information through rotation, ensuring a balance between relative and absolute encoding for optimal model performance.
Super Hot emerges as a beacon of hope in the quest to extend token context length, leveraging rotary positional embeddings to cleverly repeat positional encodings and exploit the model's token memorization. By capitalizing on rotary embeddings, the model can grasp the entire context seamlessly, paving the way for handling extensive context lengths of up to 16k or even 32k. This breakthrough underscores the power of innovative solutions in pushing the boundaries of model capabilities, setting the stage for future advancements in AI technology.

Image copyright Youtube

Image copyright Youtube
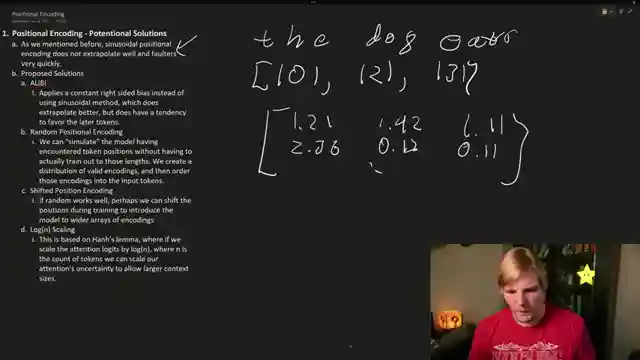
Image copyright Youtube
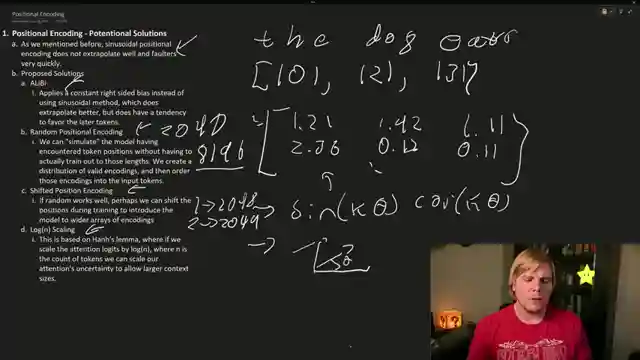
Image copyright Youtube
Watch SuperHOT, 8k and 16k Local Token Context! How Does It Work? What We Believed About LLM’s Was Wrong. on Youtube
Viewer Reactions for SuperHOT, 8k and 16k Local Token Context! How Does It Work? What We Believed About LLM’s Was Wrong.
Viewer requests for specific video topics like LLM from start to finish and exLlama explanation
Appreciation for the extra context provided in the videos
Positive feedback on the well-produced content and educational value
Comments on the misrepresentation of softmax and the dot product of vectors
Interest in topics like NTK-Aware Scaled RoPE, SuperHOT for Falcon 40B, and using oogabooga for QLoRA fine-tuning
Gratitude for the educational content and understanding gained from the videos
Related Articles

Mastering LoRA's: Fine-Tuning Language Models with Precision
Explore the power of LoRA's for training large language models in this informative guide by AemonAlgiz. Learn how to optimize memory usage and fine-tune models using the ooga text generation web UI. Master hyperparameters and formatting for top-notch performance.

Mastering Word and Sentence Embeddings: Enhancing Language Model Comprehension
Learn about word and sentence embeddings, positional encoding, and how large language models use them to understand natural language. Discover the importance of unique positional encodings and the practical applications of embeddings in enhancing language model comprehension.

Mastering Large Language Model Fine-Tuning with LoRA's
AemonAlgiz explores fine-tuning large language models with LoRA's, emphasizing model selection, data set preparation, and training techniques for optimal results.

Mastering Large Language Models: Embeddings, Training Tips, and LORA Impact
Explore the world of large language models with AemonAlgiz in a live stream discussing embeddings for semantic search, training tips, and the impact of LORA on models. Discover how to handle raw text files and leverage LLMS for chatbots and documentation.