Mastering Reinforcement Learning: PPO and TRPO Techniques Unveiled

- Authors
- Published on
- Published on
Today on AemonAlgiz, we're diving into the intricate world of reinforcement learning with human feedback, a topic so complex it makes tuning large language models seem like a walk in the park. We're talking about aligning models with user expectations, using techniques like PPO and TRPO to ensure our networks behave as we want them to. These algorithms are the backbone of ensuring our generative models don't go off the rails, generating misleading or inappropriate responses that could harm user interactions. From states to observation spaces, action spaces, and policy spaces, every element plays a crucial role in shaping our model's behavior.
Reinforcement learning is all about rewarding the good and punishing the bad, with derivatives helping us compute those all-important gradients for weight updates. The policy gradient swoops in to tweak parameters, steering our network towards the desired behavior. But hold on, it's not all smooth sailing - we need to consider discount rates, state-action value functions, and trajectories to navigate the choppy waters of reinforcement learning. And let's not forget about advantage functions, objective functions, and KL divergence when it comes to implementing PPO and TRPO.
PPO and TRPO are the knights in shining armor, nudging our network weights towards the holy grail of ideal behavior. By understanding advantage functions, objective functions, and the delicate dance of weight updates, we can ensure our models stay on the straight and narrow. But wait, there's more! Implementing these techniques in reinforcement learning from human feedback pipelines is a game-changer, offering improved performance, adaptability, and bias removal. However, challenges like scalability and subjectivity rear their ugly heads, reminding us that the road to perfecting our networks is paved with obstacles. So buckle up, folks, because the world of reinforcement learning is a thrilling ride with twists and turns at every corner.

Image copyright Youtube
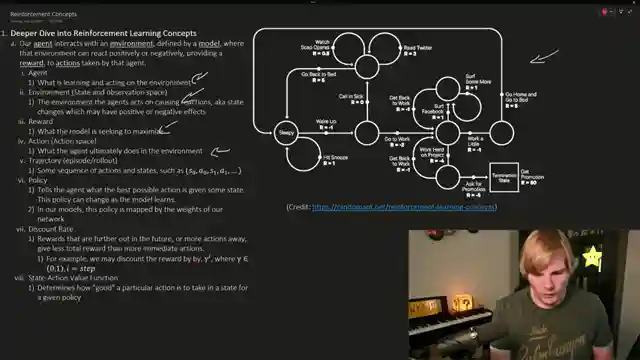
Image copyright Youtube
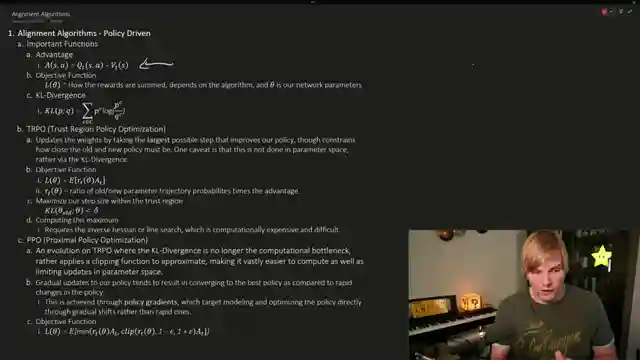
Image copyright Youtube
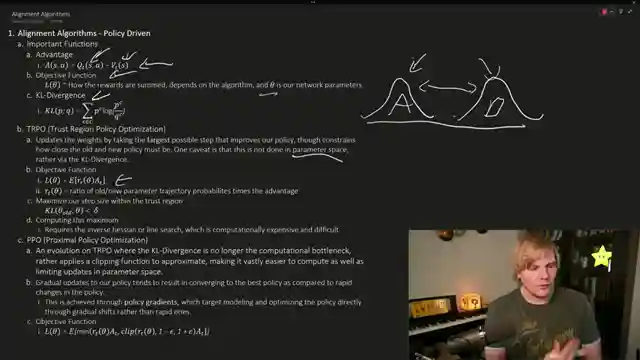
Image copyright Youtube
Watch Reinforcement Learning From Human Feedback, RLHF. Overview of the Process. Strengths and Weaknesses. on Youtube
Viewer Reactions for Reinforcement Learning From Human Feedback, RLHF. Overview of the Process. Strengths and Weaknesses.
Positive feedback on the breakdown of alignment algorithms and their work with RLHF
Viewer with basic knowledge in statistics and coding seeking book recommendations and resources to deepen understanding of machine learning concepts
Request for a link to the Google Colab used in the video
Related Articles

Mastering LoRA's: Fine-Tuning Language Models with Precision
Explore the power of LoRA's for training large language models in this informative guide by AemonAlgiz. Learn how to optimize memory usage and fine-tune models using the ooga text generation web UI. Master hyperparameters and formatting for top-notch performance.

Mastering Word and Sentence Embeddings: Enhancing Language Model Comprehension
Learn about word and sentence embeddings, positional encoding, and how large language models use them to understand natural language. Discover the importance of unique positional encodings and the practical applications of embeddings in enhancing language model comprehension.

Mastering Large Language Model Fine-Tuning with LoRA's
AemonAlgiz explores fine-tuning large language models with LoRA's, emphasizing model selection, data set preparation, and training techniques for optimal results.

Mastering Large Language Models: Embeddings, Training Tips, and LORA Impact
Explore the world of large language models with AemonAlgiz in a live stream discussing embeddings for semantic search, training tips, and the impact of LORA on models. Discover how to handle raw text files and leverage LLMS for chatbots and documentation.