Mastering Model Fine-Tuning with Landmark Attention: A Comprehensive Guide

- Authors
- Published on
- Published on
In this riveting episode by AemonAlgiz, we delve into the intricate world of Landmark attention for model fine-tuning. The team enlightens us on the crucial setup steps for oobabooga to harness Landmark attention's power, emphasizing parameter tweaks like the repetition penalty and prompt length adjustments. By selecting Trust remote code under model settings, they pave the way for a seamless integration that promises groundbreaking results.
Moving on, the guys introduce us to the realm of fine-tuning models using the cutting-edge Q LoRA implementation, enabling quantized network training for massive models locally. With step-by-step guidance on creating a conda environment and installing requirements, they ensure a smooth journey towards model optimization. The hyperparameters discussion offers a roadmap for model training success, from model selection to setting per device train batch size and gradient accumulation steps.
As the tutorial progresses, AemonAlgiz demystifies the fine-tuning process, highlighting the significance of running the command line for model training. With a nod to future developments in custom datasets support, they hint at the potential for structured training enhancements. The merge process, essential for incorporating LoRAs into the network seamlessly, is illustrated with precision, ensuring a flawless transition for optimal model performance. Through a captivating demonstration in oobabooga, the team showcases the model's prowess in retaining larger contexts effectively, setting the stage for viewers to explore wider contexts with the wizard LM.

Image copyright Youtube
Image copyright Youtube
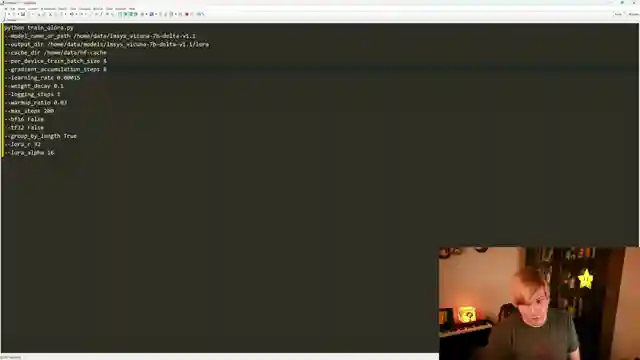
Image copyright Youtube
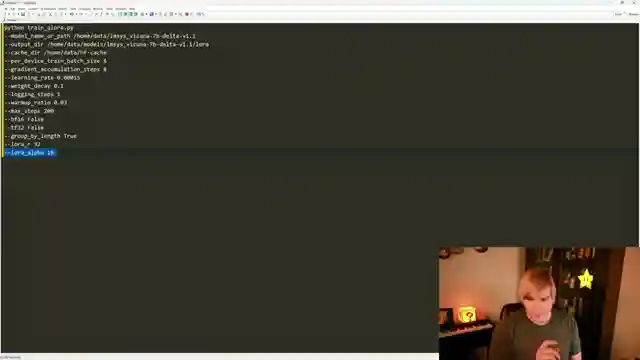
Image copyright Youtube
Watch Landmark Attention Training Walkthrough! QLoRA for Faster, Better, and Even Local Training. on Youtube
Viewer Reactions for Landmark Attention Training Walkthrough! QLoRA for Faster, Better, and Even Local Training.
Viewers appreciate the detailed explanations and demonstrations in the video
Requests for future video topics, such as training checks and graphing parameters
Questions about training with custom datasets and the possibility of training with 2 GPUs
Inquiries about merging models, training data, and the limitations of fine-tuning
Confusion about the use of Landmark Attention and how it interfaces with other models
Technical issues with running commands in oobabooga and seeking tips for resolving errors
Related Articles

Mastering LoRA's: Fine-Tuning Language Models with Precision
Explore the power of LoRA's for training large language models in this informative guide by AemonAlgiz. Learn how to optimize memory usage and fine-tune models using the ooga text generation web UI. Master hyperparameters and formatting for top-notch performance.

Mastering Word and Sentence Embeddings: Enhancing Language Model Comprehension
Learn about word and sentence embeddings, positional encoding, and how large language models use them to understand natural language. Discover the importance of unique positional encodings and the practical applications of embeddings in enhancing language model comprehension.

Mastering Large Language Model Fine-Tuning with LoRA's
AemonAlgiz explores fine-tuning large language models with LoRA's, emphasizing model selection, data set preparation, and training techniques for optimal results.

Mastering Large Language Models: Embeddings, Training Tips, and LORA Impact
Explore the world of large language models with AemonAlgiz in a live stream discussing embeddings for semantic search, training tips, and the impact of LORA on models. Discover how to handle raw text files and leverage LLMS for chatbots and documentation.