Mastering Optimization: The Efficiency of Coordinate Descent

- Authors
- Published on
- Published on
In this riveting episode, Machine Learning TV delves into the realm of optimization with the introduction of coordinate descent as a game-changing alternative to the traditional gradient descent and subgradient descent methods. The team showcases the brilliance of coordinate descent by emphasizing its approach of optimizing one dimension at a time while holding others constant, simplifying the optimization process to a single dimension problem. This strategic method eliminates the need for a step size parameter, setting it apart from the complexities of gradient descent techniques.
The adrenaline-pumping journey through the coordinate descent algorithm begins with the initialization of a vector W, paving the way for iterative updates until the algorithm reaches convergence. By strategically minimizing each dimension in sequence, coordinate descent navigates through the optimization landscape with precision and efficiency. The absence of a step size parameter in this algorithm eliminates the need for meticulous parameter tuning, offering a straightforward yet powerful approach to optimization challenges.
The versatility and effectiveness of coordinate descent shine through as the team highlights its applicability to a wide range of problems, particularly excelling in scenarios involving strongly convex objective functions and lasso regression. The algorithm's ability to guarantee convergence for specific objective functions underscores its reliability and efficiency in optimization tasks. While the episode doesn't delve into a detailed proof of convergence for lasso regression, viewers are left with a profound appreciation for the prowess of coordinate descent in tackling complex optimization problems with finesse.

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube
Watch Understanding Coordinate Descent on Youtube
Viewer Reactions for Understanding Coordinate Descent
Emily and Carlos are praised for their performance
Question about the convergence of coordinate descent using LASSO
Real data is compared to the Grand Canyon in terms of complexity
Question about using "argmin" instead of "min" in a mathematical context
Related Articles
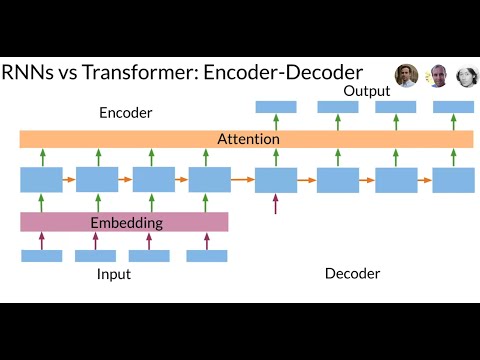
Revolutionizing Neural Networks: The Power of Transformer Models
Discover how the Transformer model revolutionizes neural networks, outperforming RNNs in sequence data processing. Say goodbye to slow computations and vanishing gradients with the Transformer's attention-based approach and multi-head layers. Embrace the future of efficient translation and sequence tasks!

Decoding Time Series Patterns: Trends, Seasonality, and Predictions
Machine Learning TV explores time series patterns like trend, seasonality, and autocorrelation, offering insights into predicting and analyzing data with real-world examples.

Mastering Language Model Evaluation: Perplexity and Text Coherence
Learn how to evaluate language models using perplexity, a key metric measuring text complexity. Split data for training, validation, and testing to assess model performance. Lower perplexity scores indicate more natural language generation. Explore bi-gram and trigram models for enhanced text coherence.

Mastering Vanishing Gradients: LSTM Solutions for RNN Efficiency
Explore how Machine Learning TV tackles the vanishing gradient problem in RNNs using LSTMs. Discover solutions like weight initialization and gradient clipping to optimize training efficiency.