Innovative Sparse Quantized Representation Technique for Enhanced AI Performance

- Authors
- Published on
- Published on
Today, the AemonAlgiz team delves into the thrilling world of cutting-edge AI research with a new paper by the legendary Tim Detmer. This paper introduces a groundbreaking sparse quantized representation technique for near-lossless LLM rate weight compression. Detmer aims for a staggering 15% boost in performance by tackling outlier weights and exploring vertical and horizontal group correlations. This isn't just any run-of-the-mill quantization method; it's a revolutionary approach that promises to shake up the AI landscape.
The team discusses the critical importance of isolating outlier weights to prevent performance degradation during quantization. By analyzing weight sensitivities and implementing bi-level quantization for small weight groups, they're pushing the boundaries of what's possible in AI compression. The graphical representation of weights offers a visual insight into sensitivity patterns, shedding light on areas that require special attention. This meticulous approach sets the stage for a new era of efficient weight compression techniques.
As the discussion unfolds, the team delves into the future of local models, pondering the potential of Landmark attention and pruning techniques to enhance model performance. They compare different quantization methods like gptq and Q Laura, highlighting the unique features of spqr. The conversation takes an exciting turn as they explore the performance of Apple's M processors and the integration of neural engines in iPhones. With a keen eye on innovation and performance, the AemonAlgiz team navigates the complex world of AI research with enthusiasm and expertise.
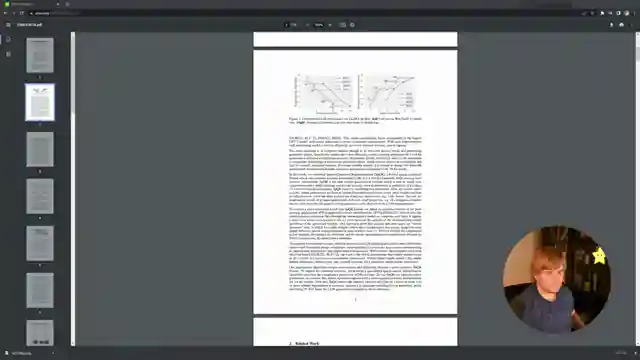
Image copyright Youtube
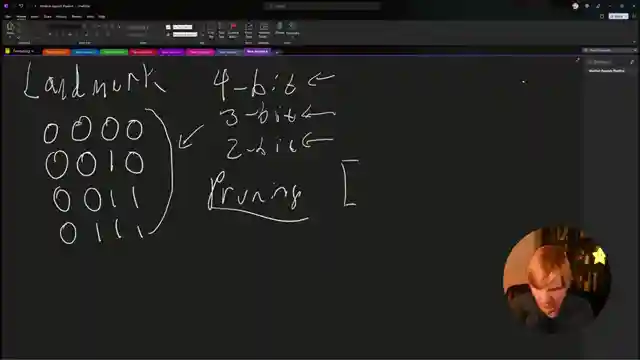
Image copyright Youtube
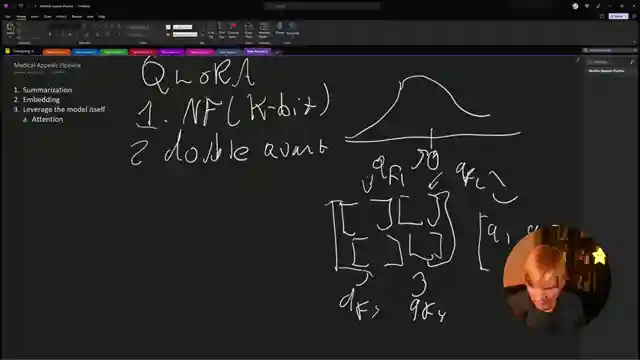
Image copyright Youtube
Image copyright Youtube
Watch SpQR - Sparse Quantization Representation - Live Stream #4 on Youtube
Viewer Reactions for SpQR - Sparse Quantization Representation - Live Stream #4
Viewer praises the YouTuber and expresses regret for missing a live stream
A viewer shares an idea about "giving memories to neural networks" and testing it on pretrained models
Request for a session comparing continue pre-train vs fine-tune vs llamaindex
Positive feedback on the content
Discussion on steering networks with activation weight symmetry
Frustration expressed about chat sidetracking the discussion on Landmark topic.
Related Articles

Mastering LoRA's: Fine-Tuning Language Models with Precision
Explore the power of LoRA's for training large language models in this informative guide by AemonAlgiz. Learn how to optimize memory usage and fine-tune models using the ooga text generation web UI. Master hyperparameters and formatting for top-notch performance.

Mastering Word and Sentence Embeddings: Enhancing Language Model Comprehension
Learn about word and sentence embeddings, positional encoding, and how large language models use them to understand natural language. Discover the importance of unique positional encodings and the practical applications of embeddings in enhancing language model comprehension.

Mastering Large Language Model Fine-Tuning with LoRA's
AemonAlgiz explores fine-tuning large language models with LoRA's, emphasizing model selection, data set preparation, and training techniques for optimal results.

Mastering Large Language Models: Embeddings, Training Tips, and LORA Impact
Explore the world of large language models with AemonAlgiz in a live stream discussing embeddings for semantic search, training tips, and the impact of LORA on models. Discover how to handle raw text files and leverage LLMS for chatbots and documentation.