Enhancing Token Context: Alibi and Landmark Attention Solutions

- Authors
- Published on
- Published on
On this episode of AemonAlgiz, we dive into the perplexing world of increasing context length for large language models. It's like trying to fit a square peg into a round hole - challenging, to say the least. The team breaks down the nitty-gritty details, from the complexities of Big O notation to the significance of embedding dimensions. Picture this: you're navigating through a maze of computational hurdles, with attention layers and embedding dimensions throwing obstacles at every turn.
But fear not, for Alibi swoops in as the knight in shining armor, armed with linear biases to tackle the context length dilemma head-on. By replacing sinusoidal positional encoding with a bias, Alibi offers a fresh perspective on enhancing token context length. Think of it as a turbo boost for your language model, revving up both performance and efficiency. It's a game-changer in the realm of large language models, paving the way for smoother sailing in the turbulent seas of computational complexity.
Enter sparse attention, a method that sifts through the noise to pinpoint the gems in the rough. By focusing on essential tokens and ignoring the rest, sparse attention streamlines the process, making the journey from quadratic to linear complexity a breeze. The team explores the concept of connectivity graphs and matrices, unraveling the mysteries of attention mechanisms with finesse. And just when you think you've seen it all, Big Bird swoops in to combine local and global strategies, offering a fresh take on context length expansion.
But wait, there's more! Landmark attention steps into the spotlight, promising a brighter future for context length augmentation. By empowering the Transformer's attention layer to identify crucial tokens, Landmark attention opens new doors in the realm of large language models. It's like giving your model a pair of high-powered binoculars, allowing it to zoom in on the most relevant information with precision. With Landmark attention at the helm, the possibilities for context length extension seem endless, promising a brighter future for language models everywhere.

Image copyright Youtube
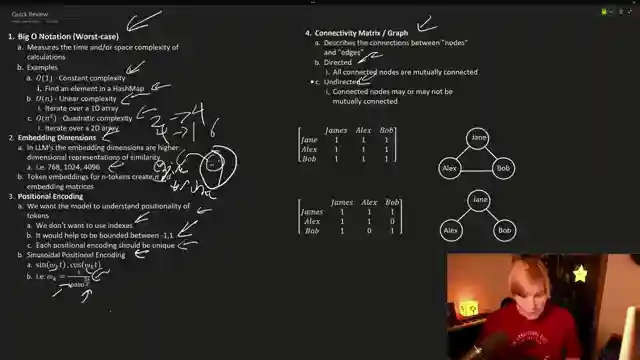
Image copyright Youtube
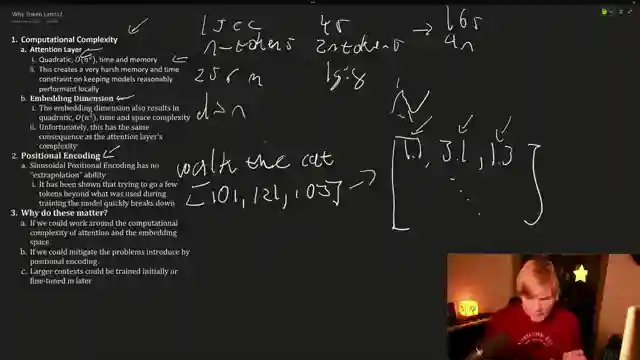
Image copyright Youtube
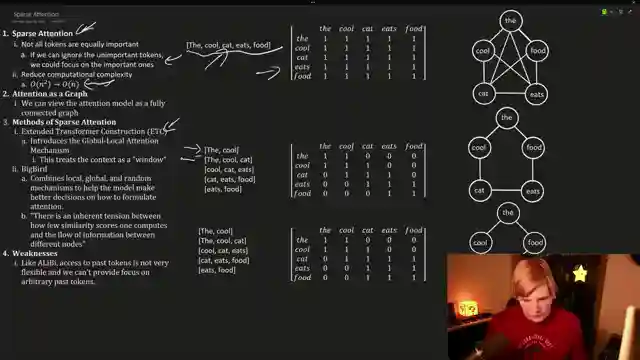
Image copyright Youtube
Watch Why Do LLM’s Have Context Limits? How Can We Increase the Context? ALiBi and Landmark Attention! on Youtube
Viewer Reactions for Why Do LLM’s Have Context Limits? How Can We Increase the Context? ALiBi and Landmark Attention!
Viewers appreciate the clear explanation of complex topics and the approachable presentation style
Some viewers suggest using a clapperboard for audio-video sync
Requests for practical examples of working with context and balancing performance vs. context length in webui
Interest in hearing about multi-modal GPT models
Discussion on attention mechanisms and landmark attention
Clarification on "big O notation" and worst case scenarios
Curiosity about the importance of being bounded between -1,1
Question about the notes written in during the video
Related Articles

Mastering LoRA's: Fine-Tuning Language Models with Precision
Explore the power of LoRA's for training large language models in this informative guide by AemonAlgiz. Learn how to optimize memory usage and fine-tune models using the ooga text generation web UI. Master hyperparameters and formatting for top-notch performance.

Mastering Word and Sentence Embeddings: Enhancing Language Model Comprehension
Learn about word and sentence embeddings, positional encoding, and how large language models use them to understand natural language. Discover the importance of unique positional encodings and the practical applications of embeddings in enhancing language model comprehension.

Mastering Large Language Model Fine-Tuning with LoRA's
AemonAlgiz explores fine-tuning large language models with LoRA's, emphasizing model selection, data set preparation, and training techniques for optimal results.

Mastering Large Language Models: Embeddings, Training Tips, and LORA Impact
Explore the world of large language models with AemonAlgiz in a live stream discussing embeddings for semantic search, training tips, and the impact of LORA on models. Discover how to handle raw text files and leverage LLMS for chatbots and documentation.