Fine-Tuning Language Models: CSV Dataset Tutorial with Abhishek Thakur

- Authors
- Published on
- Published on
In this thrilling tutorial by Abhishek Thakur, he delves into the exhilarating world of fine-tuning large language models like Lama V2 using a dynamic CSV dataset. With columns dedicated to instruction, input, and output, Abhishek showcases the adrenaline-pumping process of converting the data into a format compatible with Auto Train through a custom Python script. The dataset is transformed and saved as train.csv, setting the stage for the heart-pounding action that is about to unfold.
As the installation of Auto Train takes center stage, Abhishek revs up the excitement by detailing the essential setup steps required for this high-octane journey. The Auto Train LLM command is unleashed, initiating the pulse-quickening training process with precision parameters like learning rate and batch size. The race against time begins as the model is put through its paces, promising a nail-biting experience for all involved.
Abhishek's expert guidance doesn't stop there; he offers a glimpse into the future, teasing the possibility of loading the trained model for future use and even hints at the pulse-quickening prospect of pushing the model to the Hugging Face Hub for deployment. With a nod to the daredevils on a single GPU or the free-spirited souls on Google Colab's free version, Abhishek's advice on sharding the dataset adds a thrilling twist to the narrative, ensuring a smooth ride without any memory roadblocks.
In a riveting conclusion, Abhishek revs up the enthusiasm, urging viewers to take the wheel and embark on their own fine-tuning adventures. With an invitation to share feedback, questions, and the promise of more exhilarating content on the horizon, Abhishek's tutorial leaves the audience on the edge of their seats, hungry for more high-speed, high-stakes linguistic exploits.
Image copyright Youtube
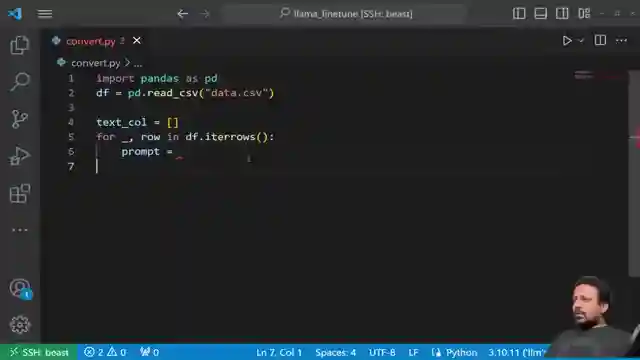
Image copyright Youtube
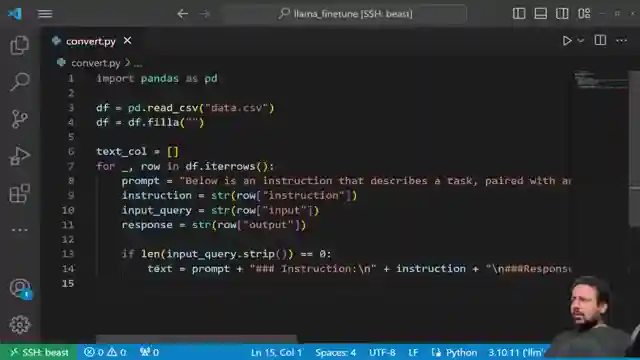
Image copyright Youtube
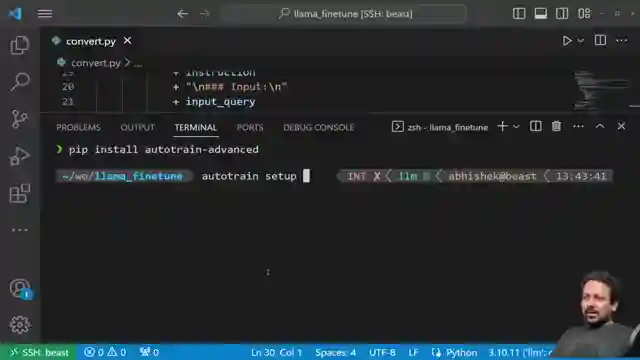
Image copyright Youtube
Watch The EASIEST way to finetune LLAMA-v2 on local machine! on Youtube
Viewer Reactions for The EASIEST way to finetune LLAMA-v2 on local machine!
Request for more videos on merging fine-tuned weights to the base model and doing inference
Confusion regarding prompt formatting used in the video
Request for more information on training hyperparameters and custom dataset sizes
Difficulty faced during installation of autotrain-advanced
Inquiry about inserting multiple input values in the CSV data
Question about training LLAMA3 using the same steps
Inquiry about accessing the LLAMA model
Recommendation for a machine to fine-tune LLAMA
Inquiry about when the trained model will be visible
Request for guidance on preparing data for training
Related Articles

Revolutionizing Image Description Generation with InstructBlip and Hugging Face Transformers
Abhishek Thakur explores cutting-edge image description generation using InstructBlip and Hugging Face Transformers. Leveraging Vicuna and Flan T5, the team crafts detailed descriptions, saves them in a CSV file, and creates embeddings for semantic search, culminating in a user-friendly Gradio demo.

Ultimate Guide: Creating AI QR Codes with Python & Hugging Face Library
Learn how to create AI-generated QR codes using Python and the Hugging Face library, Diffusers, in this exciting tutorial by Abhishek Thakur. Explore importing tools, defining models, adjusting parameters, and generating visually stunning QR codes effortlessly.
Unveiling Salesforce's Exogen: Efficient 7B LLM Model for Summarization
Explore Salesforce's cutting-edge Exogen model, a 7B LLM trained on an 8K input sequence. Learn about its Apache 2.0 license, versatile applications, and efficient summarization capabilities in this informative video by Abhishek Thakur.

Mastering LLM Training in 50 Lines: Abhishek Thakur's Expert Guide
Abhishek Thakur demonstrates training LLMs in 50 lines of code using the "alpaca" dataset. He emphasizes data formatting consistency for optimal results, showcasing the process on his home GPU. Explore the world of AI training with key libraries and fine-tuning techniques.