Unveiling the Power of Large Language Models: A Deep Dive

- Authors
- Published on
- Published on
In this riveting lecture by AI Coffee Break with Letitia, the team embarks on an adrenaline-fueled journey through the heart of large language models, focusing on the mighty Transformer architecture. They rev up the discussion by highlighting the Transformer's role as the powerhouse behind modern llms, setting the stage for a high-octane exploration of its inner workings. With the throttle wide open, they zoom into the concept of linear separability, crucial for tasks like sentence completion, fueling the llm's quest for optimal representations.
As the team shifts gears, they tackle the challenge of representing text as vectors, navigating the treacherous terrain of tokenization to conquer the hurdles posed by new words and typos. With expert precision, they dissect the feed-forward neural network component in Transformers, showcasing the art of weight sharing for lightning-fast parallel computation. The adrenaline peaks as they unveil the self-attention mechanism, a turbocharged feature that allows tokens to share vital context, unleashing the raw power of data-dependent weighted averaging within the sequence.
In a final exhilarating sprint, the team demystifies the complex linear algebra underpinning the computation of data-dependent weights for self-attention, pushing the boundaries of understanding in the roaring world of large language models. With each revelation, AI Coffee Break with Letitia revs up the engines of knowledge, taking viewers on a pulse-pounding ride through the cutting-edge technology that fuels the future of language processing. Strap in, hold on tight, and get ready to be swept away by the sheer adrenaline of unraveling the mysteries of llms in this electrifying lecture.

Image copyright Youtube
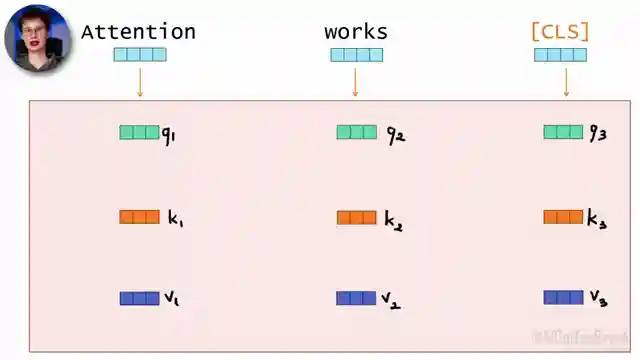
Image copyright Youtube
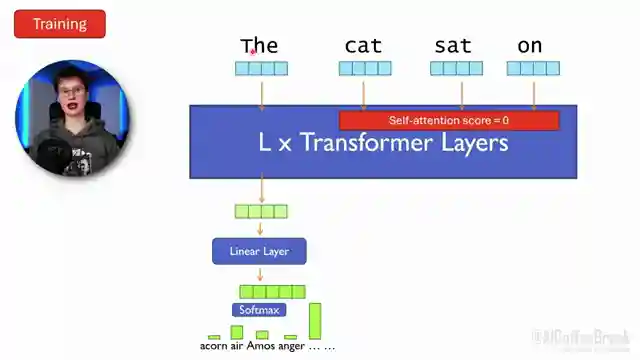
Image copyright Youtube

Image copyright Youtube
Watch LLM Lecture: A Deep Dive into Transformers, Prompts, and Human Feedback on Youtube
Viewer Reactions for LLM Lecture: A Deep Dive into Transformers, Prompts, and Human Feedback
Channel praised for providing high-quality machine learning knowledge
Specific video on LLMs highly appreciated for its clarity and comprehensiveness
Viewers express gratitude for the educational content and request for more similar videos
Request for a video on Google's new paper "Titans: Learning to Memorize at Test Time"
Request for recommendations on projects or websites to practice implementing LLMs
Some viewers mention specific parts they found interesting or challenging in the video
Request for more long videos with deep dives on tokenization-free algorithms
Question about the use of softmax in attention and its relation to hallucinations
Question about the residual connections in LLMs and whether the positional vector passes along with the input
Related Articles

Revolutionizing Video Understanding: Introducing Storm Model
Discover Storm, a groundbreaking video language model revolutionizing video understanding by compressing sequences for improved reasoning. Storm outperforms existing models on benchmarks, enhancing efficiency and accuracy in real-time applications.

Revolutionizing Large Language Model Training with FP4 Quantization
Discover how training large language models at ultra-low precision using FP4 quantization revolutionizes efficiency and performance, challenging traditional training methods. Learn about outlier clamping, gradient estimation, and the potential for FP4 to reshape the future of large-scale model training.

Revolutionizing AI Reasoning Models: The Power of a Thousand Examples
Discover how a groundbreaking paper revolutionizes AI reasoning models, showing that just a thousand examples can boost performance significantly. Test time tricks and distillation techniques make high-performance models accessible, but at a cost. Explore the trade-offs between accuracy and computational efficiency.
Revolutionizing Model Interpretability: Introducing CC-SHAP for LLM Self-Consistency
Discover the innovative CC-SHAP score introduced by AI Coffee Break with Letitia for evaluating self-consistency in natural language explanations by LLMs. This continuous measure offers a deeper insight into model behavior, revolutionizing interpretability testing in the field.