Revolutionizing AI Image Generation: REPA Loss Term Unleashed!

- Authors
- Published on
- Published on
In this riveting episode of AI Coffee Break, the team delves into a groundbreaking paper unveiling the REPA loss term for diffusion models. Picture this: diffusion models, those masters of image generation, are like students asking to copy homework from the brainy kid in class, DINOv2. By aligning with DINOv2's abstract representations, diffusion models turbocharge their training and elevate their visual prowess to new heights. It's a genius move, really. The kind that makes you wonder, "Why didn't I think of that?"
But hold onto your seats, folks, because the results are nothing short of spectacular. With the addition of the REPA loss term, diffusion models like DiT and SiT undergo a transformation, learning faster and smarter than ever before. The alignment with DINOv2's representations not only accelerates training but also enhances the models' ability to capture general-purpose visual features. It's like giving these models a cheat code to level up in the world of AI-generated visuals.
The impact is undeniable. FID scores plummet, image reconstruction reaches new heights, and image classification accuracy skyrockets. Diffusion models are no longer just good at what they do; they're exceptional. But as we revel in this triumph, questions linger. Is this alignment with other models a temporary fix, or a long-term strategy for diffusion models? And what about the limitations of models like DINOv2—could they become a roadblock in the future? It's a thrilling ride through the world of AI innovation, leaving us on the edge of our seats, eager for more breakthroughs. So buckle up, folks, because the future of AI is looking brighter than ever.

Image copyright Youtube
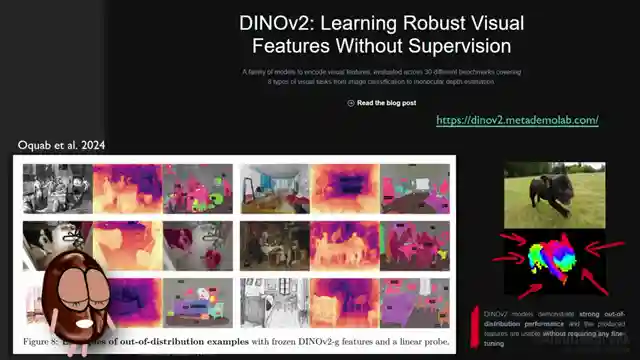
Image copyright Youtube
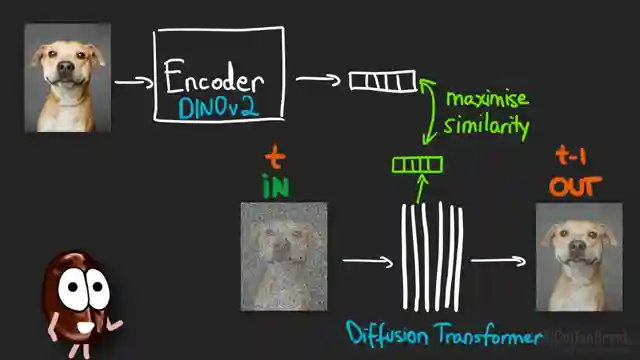
Image copyright Youtube

Image copyright Youtube
Watch REPA Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You ... on Youtube
Viewer Reactions for REPA Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You ...
MLP representation of just the 8th layer discussed
Idea of additional loss has GAN era vibes
Interest in training end to end with contrastive loss
Mention of Nvidia's normalized transformer (nGPT) and the differential transformer
Comment on the "dark ages" of high level structural encoding representations in deep learning networks
Inquiry about recording and editing tools used
Curiosity about scaling with additional external representations and changing training approach
Concerns about methodological issues, training cost, generalization, and peak accuracy shift
Not seen as a long term approach, autoregressive generative vision language models mentioned as the future
Related Articles

Revolutionizing Video Understanding: Introducing Storm Model
Discover Storm, a groundbreaking video language model revolutionizing video understanding by compressing sequences for improved reasoning. Storm outperforms existing models on benchmarks, enhancing efficiency and accuracy in real-time applications.

Revolutionizing Large Language Model Training with FP4 Quantization
Discover how training large language models at ultra-low precision using FP4 quantization revolutionizes efficiency and performance, challenging traditional training methods. Learn about outlier clamping, gradient estimation, and the potential for FP4 to reshape the future of large-scale model training.

Revolutionizing AI Reasoning Models: The Power of a Thousand Examples
Discover how a groundbreaking paper revolutionizes AI reasoning models, showing that just a thousand examples can boost performance significantly. Test time tricks and distillation techniques make high-performance models accessible, but at a cost. Explore the trade-offs between accuracy and computational efficiency.
Revolutionizing Model Interpretability: Introducing CC-SHAP for LLM Self-Consistency
Discover the innovative CC-SHAP score introduced by AI Coffee Break with Letitia for evaluating self-consistency in natural language explanations by LLMs. This continuous measure offers a deeper insight into model behavior, revolutionizing interpretability testing in the field.