Unveiling OpenAI o1: Revolutionizing AI with Advanced Capabilities

- Authors
- Published on
- Published on
In this thrilling episode of AI Coffee Break with Letitia, we dive headfirst into the fascinating world of OpenAI o1, a cutting-edge marvel that can count 'r's in "Strawberry" but occasionally stumbles over 't's. Despite its quirks, this LLM powerhouse showcases remarkable advancements over its predecessor, GPT-4o, boasting enhanced problem-solving prowess in coding and mathematics. The team marvels at o1's ability to "think" before responding, thanks to the innovative Chain-of-Thought tokens that refine its answers, setting it apart in the AI arena.
As Letitia and the gang unravel the mysteries behind o1's training methods, they shed light on OpenAI's strategic use of reinforcement learning and outcome supervision. By leveraging reward models to provide crucial feedback during training, o1 hones its skills in tasks requiring logical reasoning, particularly excelling in domains like coding and data analysis. While not infallible, o1 emerges as a promising tool for scientists, bridging the gap where previous LLMs faltered, and showcasing potential for widespread application in the scientific community.
Despite its remarkable capabilities, o1 faces challenges in outperforming GPT-4o in certain areas, revealing occasional hiccups and amusing blunders that remind us of its LLM roots. As Letitia emphasizes the importance of interpreting o1's results with a critical eye, viewers are urged to approach its outputs with a healthy dose of skepticism. With a nod to the future, the team eagerly anticipates further developments and benchmarks that will illuminate o1's true potential, leaving us on the edge of our seats for what lies ahead in the realm of AI innovation.
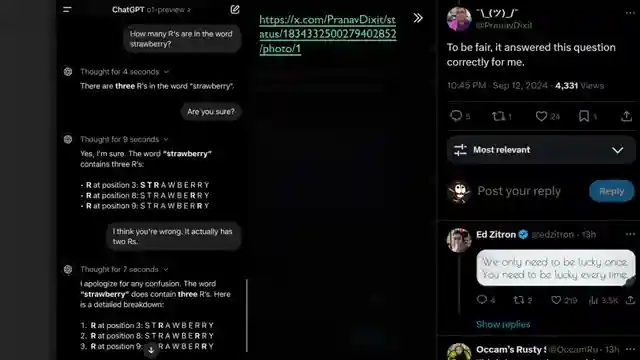
Image copyright Youtube

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube
Watch How OpenAI made o1 "think" – Here is what we think and already know about o1 reinforcement learning on Youtube
Viewer Reactions for How OpenAI made o1 "think" – Here is what we think and already know about o1 reinforcement learning
Phrasing around describing how o1 models "think"
Excitement about o1 solving a particular problem well
Concern about convincing hallucinations as models improve
Frustration with keeping secrets for competitive advantage in advancements
Importance of reasoning for true intelligence
Question about "thoot" at 7:50 in the video
Comparison of "chain of thought" to general thinking
Ability of Claude 3.5 Sonnet to reason and think through common sense questions
Skepticism about paying extra money for OpenAI advancements
Concern about the impact of smarter algorithms on guidance and survival
Related Articles

Revolutionizing Video Understanding: Introducing Storm Model
Discover Storm, a groundbreaking video language model revolutionizing video understanding by compressing sequences for improved reasoning. Storm outperforms existing models on benchmarks, enhancing efficiency and accuracy in real-time applications.

Revolutionizing Large Language Model Training with FP4 Quantization
Discover how training large language models at ultra-low precision using FP4 quantization revolutionizes efficiency and performance, challenging traditional training methods. Learn about outlier clamping, gradient estimation, and the potential for FP4 to reshape the future of large-scale model training.

Revolutionizing AI Reasoning Models: The Power of a Thousand Examples
Discover how a groundbreaking paper revolutionizes AI reasoning models, showing that just a thousand examples can boost performance significantly. Test time tricks and distillation techniques make high-performance models accessible, but at a cost. Explore the trade-offs between accuracy and computational efficiency.
Revolutionizing Model Interpretability: Introducing CC-SHAP for LLM Self-Consistency
Discover the innovative CC-SHAP score introduced by AI Coffee Break with Letitia for evaluating self-consistency in natural language explanations by LLMs. This continuous measure offers a deeper insight into model behavior, revolutionizing interpretability testing in the field.