Mastering 4-Bit Quantization: GPTQ for Llama Language Models

- Authors
- Published on
- Published on
Today on AemonAlgiz, we're diving headfirst into the thrilling world of 4-bit quantization for large language models like GPTQ. This isn't just about numbers and matrices; it's a high-octane journey into the heart of neural networks. Imagine transforming 32-bit floating point weights into compact 8 or 4-bit integers, making your network leaner and meaner. It's like swapping a luxury yacht for a speedboat - same power, more agility.
But hold on, we're not done yet. Buckle up as we rev our engines through the calculus terrain, exploring derivatives and Hessians like a pro racer navigating hairpin bends. These mathematical tools aren't just fancy jargon; they're the turbo boosters that help us fine-tune weight updates during 4-bit quantization. It's like having the perfect gear ratio for every twist and turn on the track, ensuring maximum performance without skidding off course.
And let's not forget about emergent features, the secret sauce that gives neural networks their edge. Picture layers of neurons harmonizing to label input features, like a symphony orchestra hitting all the right notes. Preserving these emergent features during quantization is crucial - it's like keeping your favorite guitar riff intact while upgrading the rest of the band. It's a delicate dance between tradition and innovation, ensuring your network stays true to its roots while embracing the future.
Now, onto the main event - the adrenaline-pumping process of 4-bit quantization. Layer by layer, we strip down our network, optimizing weights, and minimizing errors like a pit crew fine-tuning a race car. With precision tools like Hessians and inverse Hessians in our arsenal, we navigate the quantization track with finesse, ensuring a stable network that's ready to dominate the competition. So strap in, gear up, and get ready to unleash the full potential of your language model with GPTQ 4-bit quantization on Llama.

Image copyright Youtube

Image copyright Youtube
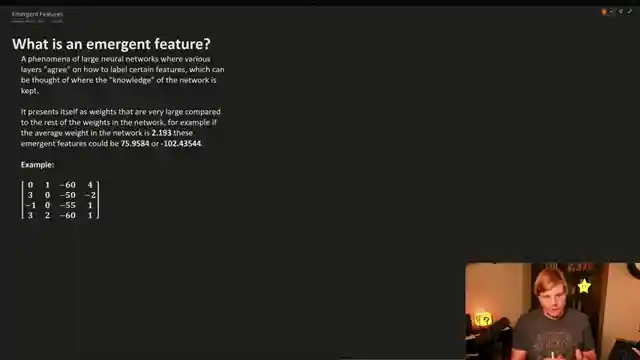
Image copyright Youtube

Image copyright Youtube
Watch LLaMa GPTQ 4-Bit Quantization. Billions of Parameters Made Smaller and Smarter. How Does it Work? on Youtube
Viewer Reactions for LLaMa GPTQ 4-Bit Quantization. Billions of Parameters Made Smaller and Smarter. How Does it Work?
Viewers appreciate the clear and concise explanations in the video
Some viewers are impressed by the level of detail and effort put into the content
Questions raised about quantization loss computation and post-training fine-tuning
Minor correction pointed out regarding the range of values for 8-bit quantization
Requests for information on specific models used in the demonstration
Suggestions for improving video quality by syncing voice with video more precisely
Inquiries about the comparison between bitsandbytes NF4 and GPTQ for quantization
Questions about running the converted model and the role of datasets in quantization
Technical issues faced by a viewer when trying to run the code on a GPU
Clarification sought on the division factor for 4-bit quantization compared to 8-bit quantization
Related Articles

Mastering LoRA's: Fine-Tuning Language Models with Precision
Explore the power of LoRA's for training large language models in this informative guide by AemonAlgiz. Learn how to optimize memory usage and fine-tune models using the ooga text generation web UI. Master hyperparameters and formatting for top-notch performance.

Mastering Word and Sentence Embeddings: Enhancing Language Model Comprehension
Learn about word and sentence embeddings, positional encoding, and how large language models use them to understand natural language. Discover the importance of unique positional encodings and the practical applications of embeddings in enhancing language model comprehension.

Mastering Large Language Model Fine-Tuning with LoRA's
AemonAlgiz explores fine-tuning large language models with LoRA's, emphasizing model selection, data set preparation, and training techniques for optimal results.

Mastering Large Language Models: Embeddings, Training Tips, and LORA Impact
Explore the world of large language models with AemonAlgiz in a live stream discussing embeddings for semantic search, training tips, and the impact of LORA on models. Discover how to handle raw text files and leverage LLMS for chatbots and documentation.