Enhancing Language Models with Embeddings: AemonAlgiz Insights

- Authors
- Published on
- Published on
Today on AemonAlgiz, we delve into the intricate world of setting up data sets to fine-tune those massive language models. Before even thinking about constructing these data sets, one must ponder the model's purpose and how to fine-tune it. This crucial decision shapes the approach to creating the data set and potentially building additional infrastructure to support the fine-tuning process. From question answering to text generation and even coding assistance, the possibilities are vast. Embeddings play a vital role in supporting these tasks, providing essential context to the models.
Embeddings, as our host explains, relate concepts in an n-dimensional space, where proximity signifies relation. By leveraging embeddings, models can gain a deeper understanding of the data they process. This additional context empowers models to interpret information more effectively. In the context of medical appeals, embeddings can enhance the model's ability to craft compelling appeals by drawing from a vast database of medical ailment documentation.
Moving forward, our journey takes us through the setup of a framework to support model infrastructure, including the utilization of embeddings. The process involves chunking documents, running them through an embedding pipeline, and storing them in a Vector DB for easy access. By querying examples from this database, the model gains valuable insights to enhance its performance. Additionally, structuring documents for fine-tuning, especially from raw text like books, can be streamlined using an llm script that converts text into a structured format for training. This approach saves time and effort, ensuring a more efficient fine-tuning process.
As we witness the fine-tuning of models for various tasks, such as writing cipher queries and medical appeals, the impact of embedded data becomes evident. By providing models with embedded information, their performance is significantly improved. This method allows for a more nuanced and accurate output without the need to cover every possible scenario individually. Whether it's coding examples, comedic scripts, or book summaries, the power of embeddings in enhancing model behavior across diverse tasks is truly remarkable. AemonAlgiz's exploration sheds light on the transformative potential of embeddings in fine-tuning large language models.

Image copyright Youtube
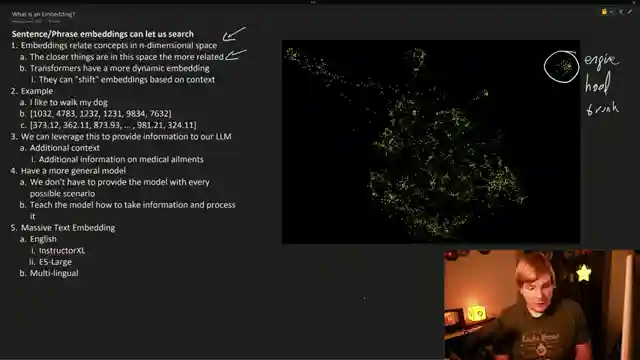
Image copyright Youtube
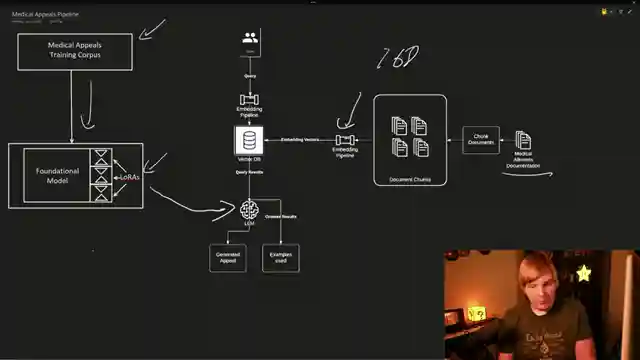
Image copyright Youtube
Image copyright Youtube
Watch How To Create Datasets for Finetuning From Multiple Sources! Improving Finetunes With Embeddings. on Youtube
Viewer Reactions for How To Create Datasets for Finetuning From Multiple Sources! Improving Finetunes With Embeddings.
Positive feedback on the quality and clarity of the content
Request for more specific tutorials on topics like fine-tuning LLMs
Questions about creating datasets and training sets
Issues with token sequence length exceeding the maximum limit of the model
Request for explanation on converting PDF to JSON and setting up web APIs
Appreciation for the practical and useful nature of the tutorials
Requests for updates and solutions to errors encountered
Curiosity about automating generation of Q&A training sets based on code
Compliments on the presentation style and depth of explanations
Suggestions for future video topics, such as preparing a dataset for creative writing
Related Articles

Mastering LoRA's: Fine-Tuning Language Models with Precision
Explore the power of LoRA's for training large language models in this informative guide by AemonAlgiz. Learn how to optimize memory usage and fine-tune models using the ooga text generation web UI. Master hyperparameters and formatting for top-notch performance.

Mastering Word and Sentence Embeddings: Enhancing Language Model Comprehension
Learn about word and sentence embeddings, positional encoding, and how large language models use them to understand natural language. Discover the importance of unique positional encodings and the practical applications of embeddings in enhancing language model comprehension.

Mastering Large Language Model Fine-Tuning with LoRA's
AemonAlgiz explores fine-tuning large language models with LoRA's, emphasizing model selection, data set preparation, and training techniques for optimal results.

Mastering Large Language Models: Embeddings, Training Tips, and LORA Impact
Explore the world of large language models with AemonAlgiz in a live stream discussing embeddings for semantic search, training tips, and the impact of LORA on models. Discover how to handle raw text files and leverage LLMS for chatbots and documentation.