Revolutionize Local LLMs: Test Time Scaling Unleashed

- Authors
- Published on
- Published on
In this thrilling episode, the 1littlecoder team unveils a groundbreaking technique called test time scaling, allowing models to think longer during inference. It's like giving your local llama a turbo boost of brainpower, resulting in enhanced intelligence and more accurate responses. They showcase the remarkable impact of this method using a code shared by an hanum, a key figure in the mlx library. By tweaking the model with a simple yet ingenious trick based on the S1 simple test time scaling paper, they demonstrate how it can correctly answer tricky questions that stump other models.
The team takes us on a wild ride through the process, showing how appending "wait" tags can make the model think longer and arrive at the right answers. Test time scaling is all about using extra compute power during inference to fine-tune the model's performance by controlling its thinking process. They share their exhilarating experiment with a 1.32 billion parameter model, revealing the magic that unfolds as they increase the thinking time. This mind-bending journey is currently exclusive to Apple computers, utilizing the mlx LM library and the Deep Seek R1 distal Quin 1.5 billion parameter model.
Despite a few bumps in the road during the demo, the team remains steadfast in their belief in the effectiveness of test time scaling. They are determined to dive deeper into this revolutionary approach and share their discoveries with llama enthusiasts worldwide. So buckle up, gearheads, and get ready to witness the future of local llm testing unfold before your eyes. It's a thrilling adventure of innovation, code, and the relentless pursuit of pushing the boundaries of what's possible in the world of language modeling.

Image copyright Youtube
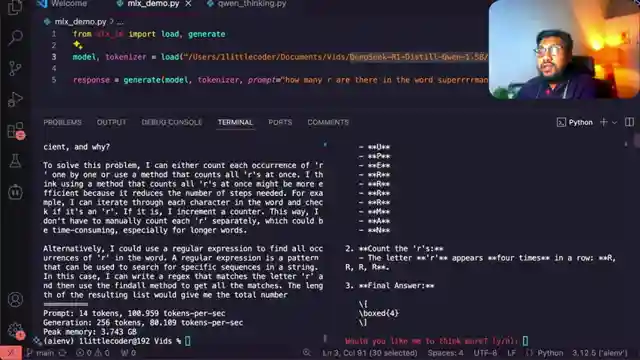
Image copyright Youtube

Image copyright Youtube
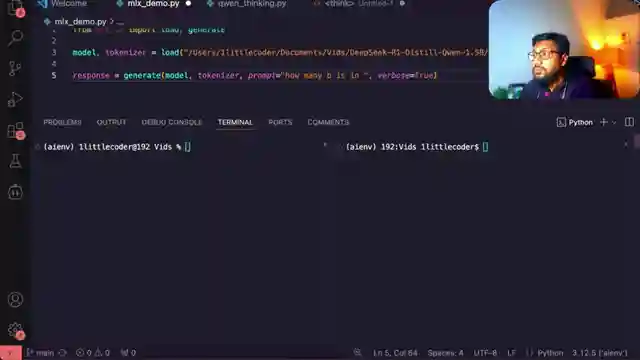
Image copyright Youtube
Watch Make Local Deepseek THINK LONGER!💥 Local Test-Time Scaling 💥 on Youtube
Viewer Reactions for Make Local Deepseek THINK LONGER!💥 Local Test-Time Scaling 💥
Positive feedback on the video content and presentation
Request for more videos on llamacpp
Interest in running a benchmark for scientific purposes
Discussion on formatting input for models and using special tags
Request for a video showing how to use the information presented
Mention of a specific paradox question to exemplify LLM reasoning
Importance of the dataset in the paper
Criticism on the approach to reproducing the effects of the paper
Question about whether the thoughts displayed by COT models consume tokens
Humorous comment about demos not working while recording
Related Articles

Revolutionizing Music Creation: Google's Magenta Real Time Model
Discover Magenta, a cutting-edge music generation model from Google deep mind. With 800 million parameters, Magenta offers real-time music creation on Google Collab TPU. Available on Hugging Face, this AI innovation is revolutionizing music production.

Nanits OCRS Model: Free Optical Character Recognition Tool Outshines Competition
Discover Nanits' OCRS model, a powerful optical character recognition tool fine-tuned from Quinn 2.5 VLM. This free model outshines Mistral AI's paid OCR API, excelling in latex equation recognition, image description, signature detection, and watermark extraction. Accessible via Google Collab, it offers seamless conversion of documents to markdown format. Experience the future of OCR technology with Nanits.

Revolutionizing Voice Technology: Chatterbox by Resemble EI
Resemble EI's Chatterbox, a half-billion parameter model licensed under MIT, excels in text-to-speech and voice cloning. Users can adjust parameters like pace and exaggeration for customized output. The model outperforms competitors, making it ideal for diverse voice applications. Subscribe to 1littlecoder for more insights.

Unlock Productivity: Google AI Studio's Branching Feature Revealed
Discover the hidden Google AI studio feature called branching on 1littlecoder. This revolutionary tool allows users to create different conversation timelines, boosting productivity and enabling flexible communication. Branching is a game-changer for saving time and enhancing learning experiences.