Master Reasoning Model Training: 3 Billion Parameter Quin Model Tutorial

- Authors
- Published on
- Published on
In this riveting tutorial by 1littlecoder, they dive headfirst into the world of training a reasoning model using a 3 billion parameter Quin model. Thanks to the brilliant minds of researchers and the efforts of unslot, viewers are taken on a thrilling ride through the process of installing essential packages like diffusers and TRL. The team doesn't stop there; they boldly venture into patching grpo algorithms and loading the Quin model, setting the stage for an epic training session.
Customization is the name of the game as 1littlecoder emphasizes the importance of tweaking parameters like sequence length and rank to match the available compute power. With a nod to efficiency, the tutorial guides viewers through enabling VM, loading the quantized model, and carefully setting up reward functions crucial for the success of reinforcement learning. Data preparation takes center stage as datasets like GSM 8K are formatted to fuel the model's prowess in math reasoning.
As the tutorial unfolds, the team delves into the intricate world of defining reward functions, including correctness and format rewards, to ensure the model is incentivized to perform at its peak. The training parameters, such as batch size and number of generations, are dissected to showcase their impact on memory consumption and training speed. Through daring experiments with different datasets and training configurations, viewers are encouraged to push the boundaries and unlock the full potential of their reasoning model.

Image copyright Youtube
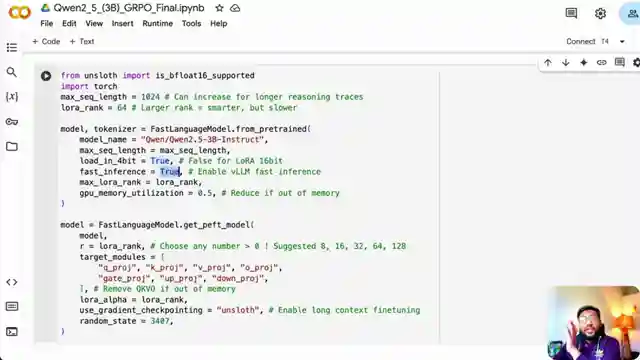
Image copyright Youtube
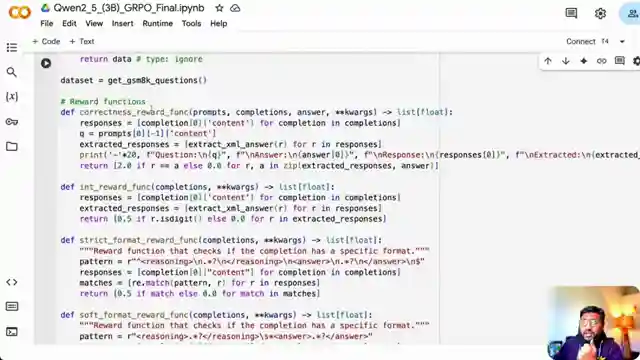
Image copyright Youtube
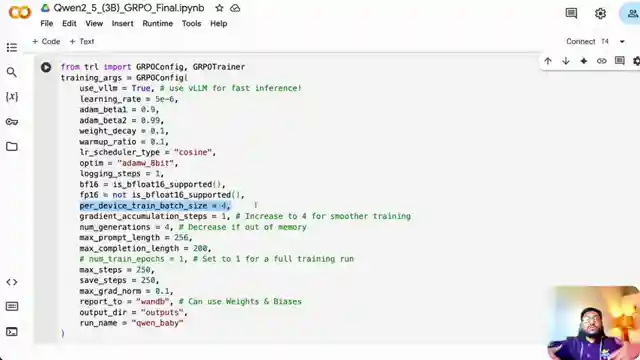
Image copyright Youtube
Watch This ONE TRICK Turns your LLM like DeepSeek R1💥 Train your own DeepLlama for Free! 💥 on Youtube
Viewer Reactions for This ONE TRICK Turns your LLM like DeepSeek R1💥 Train your own DeepLlama for Free! 💥
Viewers appreciate the improvement in the presenter's English and find the video helpful and practical.
Some viewers have been following the channel for several years and commend the presenter for staying up to date with the latest breakthroughs.
There are comments expressing gratitude for the detailed tutorial and for sharing information on costs and running the model on different platforms.
Specific technical details are shared, such as training times, model specifications, and compatibility with different operating systems.
Viewers are eager to try the model with different datasets, fine-tuning for other use cases, and exploring multimodal capabilities.
Questions are raised about running the model on different hardware like Lambda Labs and the file size of the trained LORA model.
Related Articles

Revolutionizing Music Creation: Google's Magenta Real Time Model
Discover Magenta, a cutting-edge music generation model from Google deep mind. With 800 million parameters, Magenta offers real-time music creation on Google Collab TPU. Available on Hugging Face, this AI innovation is revolutionizing music production.

Nanits OCRS Model: Free Optical Character Recognition Tool Outshines Competition
Discover Nanits' OCRS model, a powerful optical character recognition tool fine-tuned from Quinn 2.5 VLM. This free model outshines Mistral AI's paid OCR API, excelling in latex equation recognition, image description, signature detection, and watermark extraction. Accessible via Google Collab, it offers seamless conversion of documents to markdown format. Experience the future of OCR technology with Nanits.

Revolutionizing Voice Technology: Chatterbox by Resemble EI
Resemble EI's Chatterbox, a half-billion parameter model licensed under MIT, excels in text-to-speech and voice cloning. Users can adjust parameters like pace and exaggeration for customized output. The model outperforms competitors, making it ideal for diverse voice applications. Subscribe to 1littlecoder for more insights.

Unlock Productivity: Google AI Studio's Branching Feature Revealed
Discover the hidden Google AI studio feature called branching on 1littlecoder. This revolutionary tool allows users to create different conversation timelines, boosting productivity and enabling flexible communication. Branching is a game-changer for saving time and enhancing learning experiences.