Optimizing Video Processing with Semantic Chunkers: A Practical Guide

- Authors
- Published on
- Published on
In this riveting episode, James Briggs delves into the fascinating world of processing videos with semantic chunkers. These chunkers, typically used in text processing, are now making waves in the realm of audio and video. By pinpointing where video content shifts, semantic chunking revolutionizes the efficiency of video processing. James demonstrates the practical application of the semantic chunkers Library in splitting videos based on content changes, showcasing the power of this innovative tool.
With the aid of a vision Transformer encoder, James navigates through the process, fine-tuning the threshold to achieve optimal splits within the video. The use of different models like the clip encoder adds a layer of sophistication, offering a more nuanced understanding of video content. Through meticulous testing, James reveals how the clip model successfully identifies crucial scene changes, enhancing performance and accuracy in video processing.
The implications of semantic chunking extend beyond mere efficiency, offering a cost-effective solution for feeding video frames into AI models. By streamlining the processing of video data, semantic chunking emerges as a game-changer in the world of artificial intelligence. James' exploration of video chunking not only sheds light on its practical applications but also underscores its significance in enhancing the overall efficiency and effectiveness of video processing techniques.

Image copyright Youtube
Image copyright Youtube
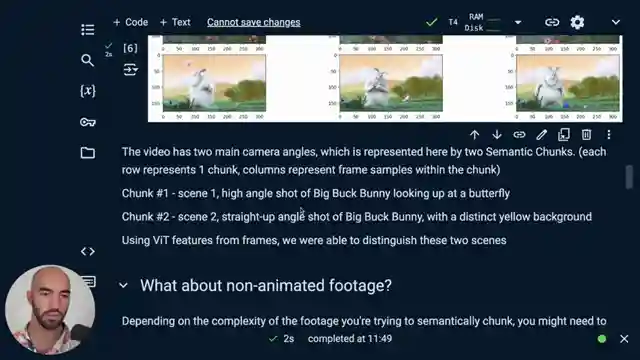
Image copyright Youtube
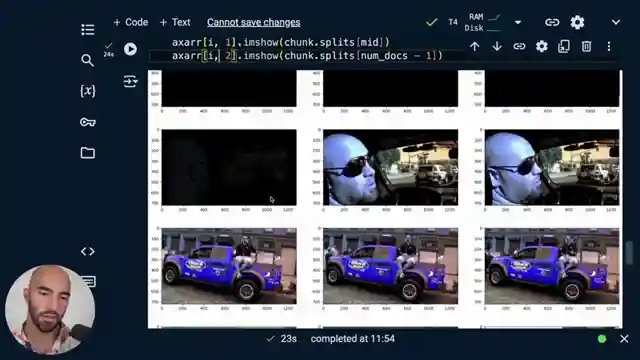
Image copyright Youtube
Watch Processing Videos for GPT-4o and Search on Youtube
Viewer Reactions for Processing Videos for GPT-4o and Search
Why chunk video and benefits of semantic chunking
Implementation of semantic chunking using the semantic-chunkers library
Model selection: Vision Transformer (ViT) vs CLIP
Comparison with scene detection in ffmpeg or perceptual hashes
Interest in algorithm behind different types of chunkers in the library
Ability of video semantic chunker to detect content changes in a presentation slide
Inquiry about js/ts based libraries for similar functionality
Trouble with colors caused by OpenCV and matplotlib
Interest in real-time AI video processing
Curiosity about achieving real-time AI animation of someone talking
Related Articles

Exploring AI Agents and Tools in Lang Chain: A Deep Dive
Lang Chain explores AI agents and tools, crucial for enhancing language models. The video showcases creating tools, agent construction, and parallel tool execution, offering insights into the intricate world of AI development.

Mastering Conversational Memory in Chatbots with Langchain 0.3
Langchain explores conversational memory in chatbots, covering core components and memory types like buffer and summary memory. They transition to a modern approach, "runnable with message history," ensuring seamless integration of chat history for enhanced conversational experiences.

Mastering AI Prompts: Lang Chain's Guide to Optimal Model Performance
Lang Chain explores the crucial role of prompts in AI models, guiding users through the process of structuring effective prompts and invoking models for optimal performance. The video also touches on future prompting for smaller models, enhancing adaptability and efficiency.

Enhancing AI Observability with Langmith and Linesmith
Langmith, part of Lang Chain, offers AI observability for LMS and agents. Linesmith simplifies setup, tracks activities, and provides valuable insights with minimal effort. Obtain an API key for access to tracing projects and detailed information. Enhance observability by making functions traceable and utilizing filtering options in Linesmith.