Accelerate Language Processing: Gro API and Llama 3 Integration Guide

- Authors
- Published on
- Published on
In this riveting video from James Briggs, we dive headfirst into the thrilling world of the Gro API paired with the formidable Llama 3 for rag. Picture this: lightning-fast access to a Language Processing Unit (LPU) that turbocharges your LMS token throughput. It's like strapping a rocket to your back as you hurtle through the digital universe at breakneck speed. The team takes us on a wild ride through the Panco examples repo, guiding us to the Gro Llama 3 rag notebook on Collab where the magic unfolds.
With the adrenaline pumping, the crew gears up by installing essential libraries like hooking face datasets, Gro API, semantic router, and Pinecone for embedding storage. They unleash the power of a dataset of AI archive papers, meticulously semantically chunked for optimal performance. As the stage is set, an encoder model E5 steps into the spotlight, boasting a longer context length to handle the data deluge with finesse. It's like watching a high-octane race where every move counts towards victory.
As the engines roar to life, the Pinecone API key is seamlessly integrated using a serverless approach, paving the way for vectors to be added in strategic batches. The team doesn't hold back, embedding both titles and content to enrich the context and elevate the search results to new heights. The thrill of the chase intensifies as a retrieval function is unleashed, deftly handling queries with the precision of a seasoned race car driver. And when the Grock API joins the fray, the Llama 3's 70 billion parameter version emerges as a true powerhouse, delivering lightning-quick responses to every challenge thrown its way.
In a heart-stopping finale, the video showcases the jaw-dropping speed and accuracy of the Gro API with Llama 3, proving to be a game-changer in the realm of large language models. The seamless integration of Grock with agent flows promises a future where quick, efficient responses are the norm, thanks to the mighty Llama 370b model leading the charge. James Briggs has unlocked a realm where open-source LMS and cutting-edge services converge, simplifying the complex and making the impossible, possible. It's a high-octane adventure where speed, power, and precision collide in a symphony of technological marvels.

Image copyright Youtube
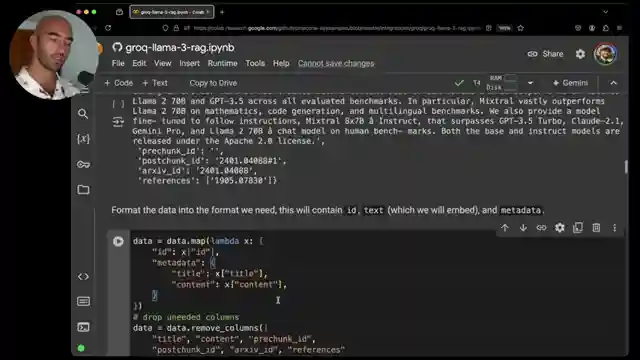
Image copyright Youtube
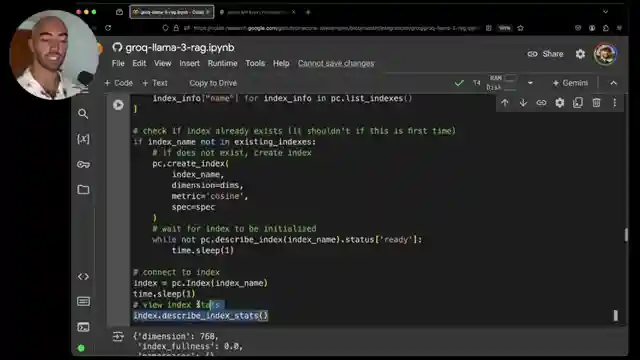
Image copyright Youtube
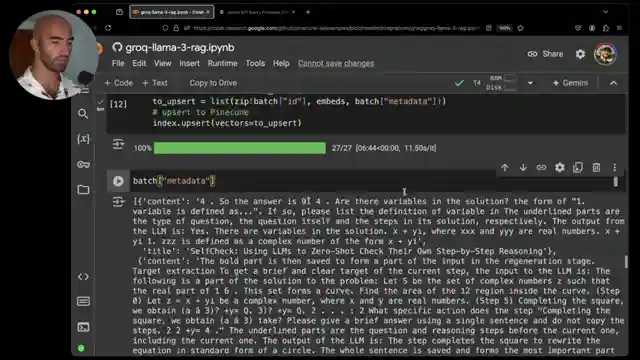
Image copyright Youtube
Watch Superfast RAG with Llama 3 and Groq on Youtube
Viewer Reactions for Superfast RAG with Llama 3 and Groq
Microsoft open-sourced their graphRAG technology stack
Groq is amazing but users wish they had other models
Groq can be used with langchain
Suggestions on adding a short summary description of the document or paper in each chunk
Recommendation for an oss embedding model over e5 for real/prod use cases
Groq is insanely fast
Interest in an online job and being in Bali
Request for converting an end-to-end project
Inquiry about reusability to switch calling Groq to call other models like OpenAI GPT-4o
Related Articles

Exploring AI Agents and Tools in Lang Chain: A Deep Dive
Lang Chain explores AI agents and tools, crucial for enhancing language models. The video showcases creating tools, agent construction, and parallel tool execution, offering insights into the intricate world of AI development.

Mastering Conversational Memory in Chatbots with Langchain 0.3
Langchain explores conversational memory in chatbots, covering core components and memory types like buffer and summary memory. They transition to a modern approach, "runnable with message history," ensuring seamless integration of chat history for enhanced conversational experiences.

Mastering AI Prompts: Lang Chain's Guide to Optimal Model Performance
Lang Chain explores the crucial role of prompts in AI models, guiding users through the process of structuring effective prompts and invoking models for optimal performance. The video also touches on future prompting for smaller models, enhancing adaptability and efficiency.

Enhancing AI Observability with Langmith and Linesmith
Langmith, part of Lang Chain, offers AI observability for LMS and agents. Linesmith simplifies setup, tracks activities, and provides valuable insights with minimal effort. Obtain an API key for access to tracing projects and detailed information. Enhance observability by making functions traceable and utilizing filtering options in Linesmith.