Master Voice Cloning with Bark Model: Abhishek Thakur's Guide

- Authors
- Published on
- Published on
In this riveting episode of Abhishek Thakur's YouTube channel, we witness the sheer power of the bark model in generating lifelike voices with unparalleled precision. With just a single model, Abhishek unveils the magic of voice cloning, requiring a mere 10-second audio snippet. Developed by suno, the bark model, a Transformer-based text-to-audio marvel, boasts the ability to create not only realistic voices but also multilingual speech and even background music and sound effects. It's a machine learning extravaganza that promises to revolutionize the way we interact with technology.
Abhishek takes us on a journey through the intricate process of utilizing the bark model, from updating Transformers versions to importing AutoProcessor and creating a seamless function for text generation. By delving into the world of voice presets offered by bark, viewers are treated to a diverse array of voice options in different languages, each adding a unique flair to the audio output. The model's versatility shines through as it seamlessly incorporates laughter, music, and other effects into the generated audio, elevating the experience to new heights of creativity.
Transitioning to the realm of voice cloning, Abhishek introduces the TTS package by kokui AI as the key player in replicating voices like the iconic Obama. Through a meticulous process involving configuration initialization, checkpoint loading, and voice synthesis, Abhishek demonstrates how anyone can clone voices with astonishing accuracy. The fusion of cutting-edge technology with user-friendly applications opens up a world of possibilities, inviting viewers to embark on their voice cloning adventures with confidence and excitement.
Image copyright Youtube
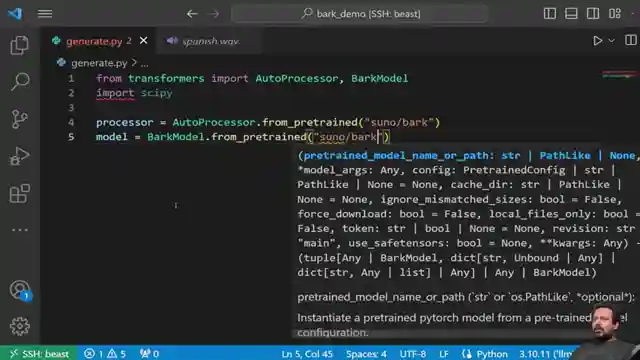
Image copyright Youtube
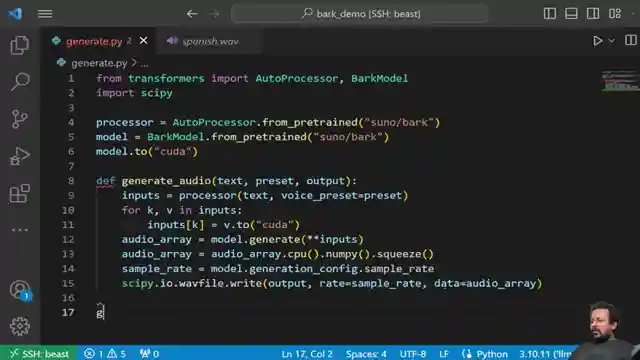
Image copyright Youtube
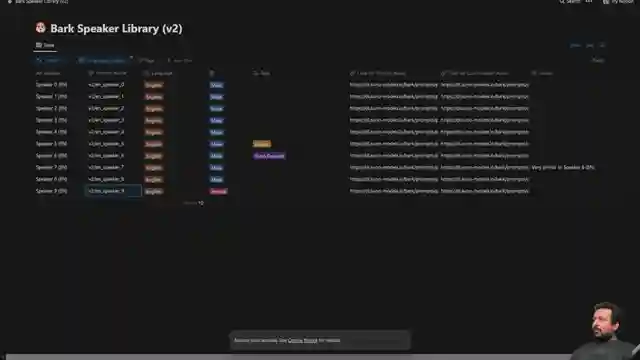
Image copyright Youtube
Watch BARK: Free Text to Speech & Voice Cloning on Youtube
Viewer Reactions for BARK: Free Text to Speech & Voice Cloning
Request for the link to the bark repository used in the video
Inquiries about improving the quality of generated content
Issues with UnpicklingError and suggestions for solutions
Difficulty in finding specific files or repositories mentioned in the video
Request for more detailed code or steps to follow
Request for specific video topics, such as training a multitasking model in computer vision
Inquiries about reducing latency in text-to-speech applications
Questions about modifying voice pitch and speed in the generated speech
Request for the full code or repository of the AAAML book
Interest in learning how to develop a text-to-speech model independently
Related Articles

Revolutionizing Image Description Generation with InstructBlip and Hugging Face Transformers
Abhishek Thakur explores cutting-edge image description generation using InstructBlip and Hugging Face Transformers. Leveraging Vicuna and Flan T5, the team crafts detailed descriptions, saves them in a CSV file, and creates embeddings for semantic search, culminating in a user-friendly Gradio demo.

Ultimate Guide: Creating AI QR Codes with Python & Hugging Face Library
Learn how to create AI-generated QR codes using Python and the Hugging Face library, Diffusers, in this exciting tutorial by Abhishek Thakur. Explore importing tools, defining models, adjusting parameters, and generating visually stunning QR codes effortlessly.
Unveiling Salesforce's Exogen: Efficient 7B LLM Model for Summarization
Explore Salesforce's cutting-edge Exogen model, a 7B LLM trained on an 8K input sequence. Learn about its Apache 2.0 license, versatile applications, and efficient summarization capabilities in this informative video by Abhishek Thakur.

Mastering LLM Training in 50 Lines: Abhishek Thakur's Expert Guide
Abhishek Thakur demonstrates training LLMs in 50 lines of code using the "alpaca" dataset. He emphasizes data formatting consistency for optimal results, showcasing the process on his home GPU. Explore the world of AI training with key libraries and fine-tuning techniques.