Unveiling the Power of Vision Language Models: Text and Image Fusion

- Authors
- Published on
- Published on
In this riveting episode by IBM Technology, we delve into the thrilling world of vision language models (VLMs) and their heroic quest to bridge the gap between text and images. Large language models (LLMs) may rule the text-processing realm with an iron fist, but when faced with images, graphs, or handwritten notes, they cower in fear. Enter VLMs, the fearless warriors of the digital age, armed with the power to interpret both text and visual data to provide text-based responses that leave LLMs in the dust.
With VLMs at the helm, tasks like visual question answering (VQA) and image captioning become a walk in the park. Show a VLM a bustling city street, and it won't just see pixels – it'll decipher the objects, people, and context, painting a vivid picture with its textual response. But VLMs aren't just about pretty pictures; they're also masters of document understanding. From scanning receipts to analyzing data-heavy visuals in PDFs, these models can extract, organize, and summarize information with the finesse of a seasoned detective.
The secret sauce behind VLMs' magic lies in their ability to merge text and images seamlessly. By introducing a vision encoder to transform images into feature vectors and a projector to map these vectors into token-based formats, VLMs pave the way for LLMs to process visual data effortlessly. However, challenges like tokenization bottlenecks and biases lurking in training data pose formidable foes on VLMs' path to glory, threatening the accuracy of their interpretations. As we journey through the realm of vision language models, we witness a digital revolution where LLMs evolve from mere readers to visionary thinkers, capable of seeing, interpreting, and reasoning about the world in ways that mirror our own visual prowess.

Image copyright Youtube
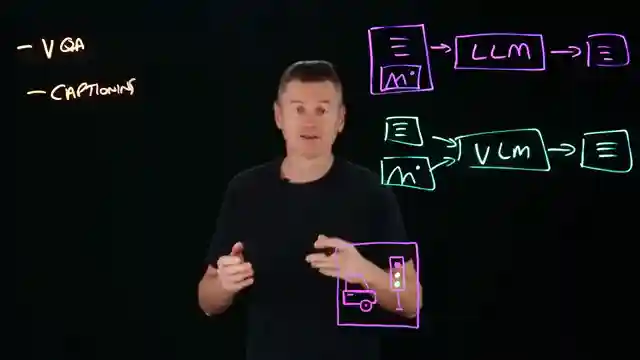
Image copyright Youtube

Image copyright Youtube
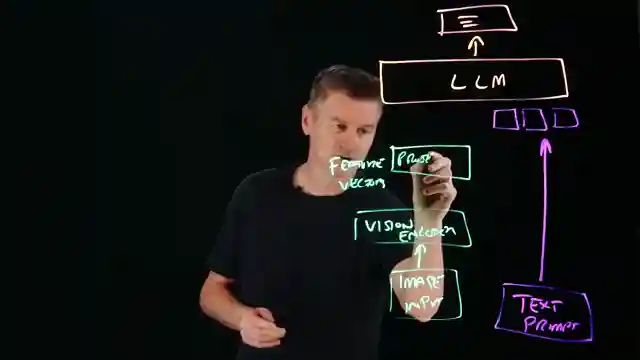
Image copyright Youtube
Watch What Are Vision Language Models? How AI Sees & Understands Images on Youtube
Viewer Reactions for What Are Vision Language Models? How AI Sees & Understands Images
Introduction to Vision Language Models and Their Capabilities
Technical Architecture of Vision Language Models
Challenges and Limitations of Vision Language Models
STEM communication
Reporting Culture
Reading Technology
One step translation
Quality data assessment
Precision medicine
How does the projector stage work?
Related Articles

Mastering Identity Propagation in Agentic Systems: Strategies and Challenges
IBM Technology explores challenges in identity propagation within agentic systems. They discuss delegation patterns and strategies like OAuth 2, token exchange, and API gateways for secure data management.

AI vs. Human Thinking: Cognition Comparison by IBM Technology
IBM Technology explores the differences between artificial intelligence and human thinking in learning, processing, memory, reasoning, error tendencies, and embodiment. The comparison highlights unique approaches and challenges in cognition.

AI Job Impact Debate & Market Response: IBM Tech Analysis
Discover the debate on AI's impact on jobs in the latest IBM Technology episode. Experts discuss the potential for job transformation and the importance of AI literacy. The team also analyzes the market response to the Scale AI-Meta deal, prompting tech giants to rethink data strategies.

Enhancing Data Security in Enterprises: Strategies for Protecting Merged Data
IBM Technology explores data utilization in enterprises, focusing on business intelligence and AI. Strategies like data virtualization and birthright access are discussed to protect merged data, ensuring secure and efficient data access environments.