Unveiling Deep Seek R1: Reinforcement Learning Revolution

- Authors
- Published on
- Published on
In this riveting episode by 1littlecoder, the team delves into the groundbreaking creation of the Deep Seek R1 model, a true game-changer in the realm of language models. Bucking the trend of traditional pre-training methods, Deep Seek R1 takes a bold leap by focusing solely on post-training, setting it apart from its predecessors. Powered by the robust Deep Seek V3 base model, a cutting-edge mixture of experts model, Deep Seek R1 harnesses the power of reinforcement learning, specifically the grpo algorithm, to push the boundaries of language model development.
With a daring 10,000 reinforcement learning steps, the team meticulously crafted Deep Seek R1, surpassing the performance of the earlier Deep Seek R10 model in key benchmarks. While Deep Seek R10 showcased exceptional reasoning abilities, it grappled with issues like language inconsistency and readability, prompting the evolution into the more refined Deep Seek R1. By incorporating cold start data, supervised fine-tuning, and reinforcement learning techniques, Deep Seek R1 emerged as a formidable contender in the competitive landscape of language models.
Not stopping at Deep Seek R1, the team embarked on a journey to distill the model's prowess into smaller, more efficient versions. Through a meticulous distillation process, they birthed a range of distilled models based on Deep Seek R1, demonstrating superior performance despite their reduced parameter counts. This innovative approach underscores the team's commitment to pushing the boundaries of language model development, showcasing the transformative power of reinforcement learning and distillation techniques in shaping the future of AI technology.
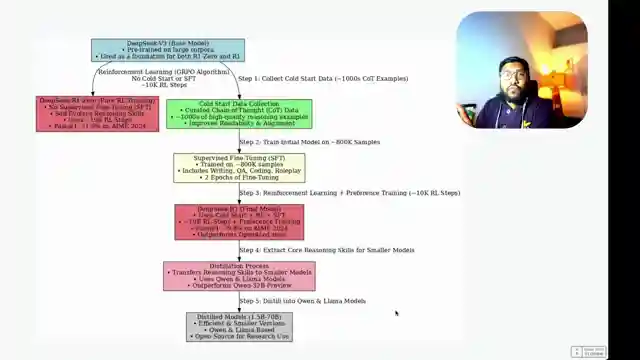
Image copyright Youtube
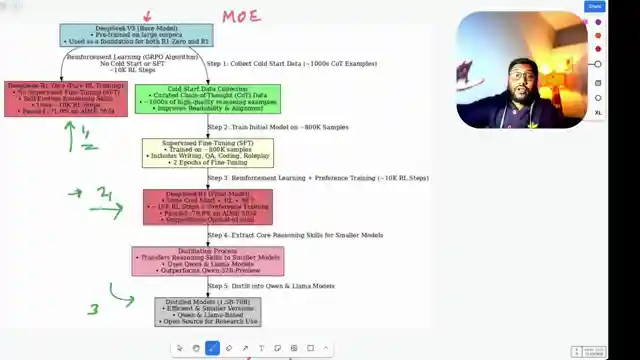
Image copyright Youtube
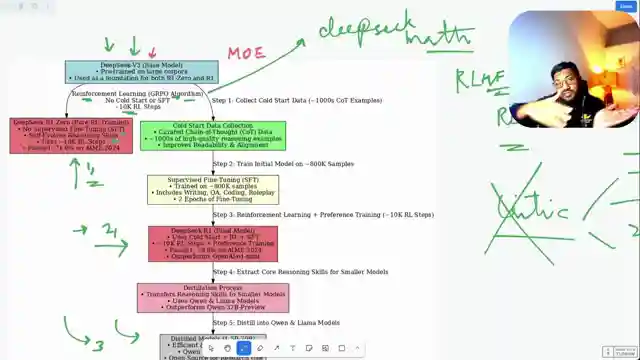
Image copyright Youtube
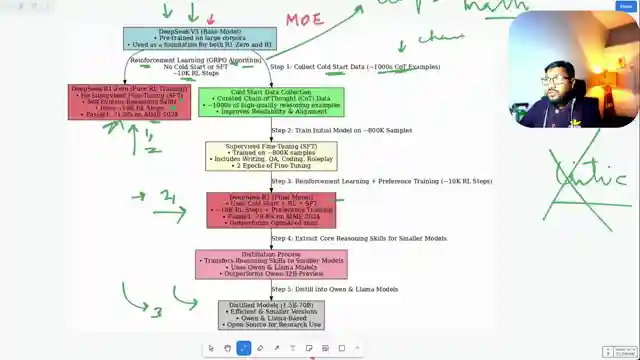
Image copyright Youtube
Watch Deepseek Decoded in 14 Mins!!! on Youtube
Viewer Reactions for Deepseek Decoded in 14 Mins!!!
Positive feedback on the video and appreciation for making AI concepts easier to understand
Requests for high-resolution images and sharing of specific models (Kimi model, TinyZero LLM training process)
Technical questions and discussions on model comparisons and training processes
Suggestions for improvement such as fixing microphone clipping and exposure
Requests for guides on specific topics like Unsloth GRPO using Kaggle
Comments on the potential of LLM technology and its implications
Mixed opinions on the effectiveness of the model in real-world scenarios
Mention of Open Source and discussions on proprietary systems
Technical comments on training paradigms and human intelligence
Reminder about rule-based reinforcement training not being mentioned in the video
Related Articles

Revolutionizing Music Creation: Google's Magenta Real Time Model
Discover Magenta, a cutting-edge music generation model from Google deep mind. With 800 million parameters, Magenta offers real-time music creation on Google Collab TPU. Available on Hugging Face, this AI innovation is revolutionizing music production.

Nanits OCRS Model: Free Optical Character Recognition Tool Outshines Competition
Discover Nanits' OCRS model, a powerful optical character recognition tool fine-tuned from Quinn 2.5 VLM. This free model outshines Mistral AI's paid OCR API, excelling in latex equation recognition, image description, signature detection, and watermark extraction. Accessible via Google Collab, it offers seamless conversion of documents to markdown format. Experience the future of OCR technology with Nanits.

Revolutionizing Voice Technology: Chatterbox by Resemble EI
Resemble EI's Chatterbox, a half-billion parameter model licensed under MIT, excels in text-to-speech and voice cloning. Users can adjust parameters like pace and exaggeration for customized output. The model outperforms competitors, making it ideal for diverse voice applications. Subscribe to 1littlecoder for more insights.

Unlock Productivity: Google AI Studio's Branching Feature Revealed
Discover the hidden Google AI studio feature called branching on 1littlecoder. This revolutionary tool allows users to create different conversation timelines, boosting productivity and enabling flexible communication. Branching is a game-changer for saving time and enhancing learning experiences.