Unlocking RAG Efficiency: Mistro API and Advanced Embedding Techniques

- Authors
- Published on
- Published on
Today, we delve into the realm of Mistro API for RAG, featuring the cutting-edge Mistro embed model and the formidable Misto large LM. Misto, a trailblazing LM AI company, takes a unique approach by open-sourcing their models and providing top-notch API services for seamless accessibility. Their models, exemplified by the game-changing Mixture of Experts, offer a level of versatility and functionality unparalleled by other open-source counterparts. The introduction of the API further streamlines the utilization of these exceptional models, making the entire process a breeze.
In this exhilarating demonstration using Pine Cone examples, the setup process kicks off with the installation of essential datasets, the Misto AI client, and Pine Cone for efficient storage and retrieval of embeddings. Data restructuring is undertaken to ensure compatibility with Pine Cone, involving the inclusion of ID and metadata fields for optimal organization. The connection to Misto is established to initiate the generation of embeddings utilizing the powerful Misto embed model. Subsequently, the setup for Pine Cone necessitates the acquisition of an API key and the initialization of an index with precise model specifications.
The journey continues with the implementation of an embedding function that adeptly handles token limits, dynamically adjusting batch sizes as needed to avoid any hiccups during the processing phase. The embedding loop then swings into action, systematically embedding data and integrating it into Pine Cone for efficient storage. By incorporating both title and content in the embeddings, a richer context is achieved, enhancing the search capabilities and overall effectiveness of the system. The testing phase involves querying the Misto LM to retrieve pertinent metadata, setting the stage for the impressive generation component utilizing the Mixture large model for crafting insightful responses.

Image copyright Youtube
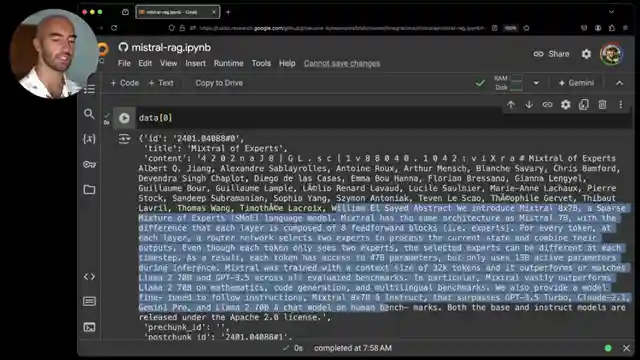
Image copyright Youtube
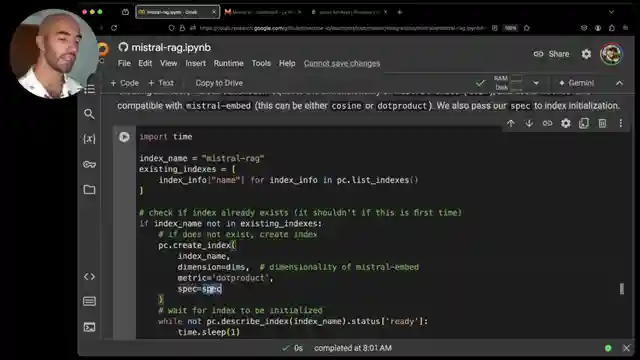
Image copyright Youtube
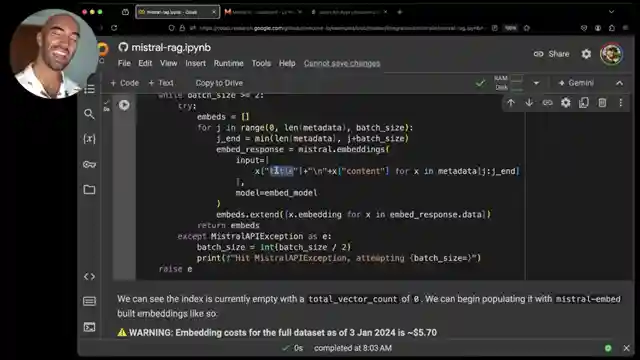
Image copyright Youtube
Watch RAG with Mistral AI! on Youtube
Viewer Reactions for RAG with Mistral AI!
Code for the demo is available on GitHub
Reminder to use region="us-east-1" for free tier usage of Pinecone
Request for more resources on adding metadata to embeddings for recommendations
Question about whether to include metadata like title, dates, author in embeddings or use traditional index
Concern about the promotion of Pinecone in the video and the need to purchase it for replication
Related Articles

Exploring AI Agents and Tools in Lang Chain: A Deep Dive
Lang Chain explores AI agents and tools, crucial for enhancing language models. The video showcases creating tools, agent construction, and parallel tool execution, offering insights into the intricate world of AI development.

Mastering Conversational Memory in Chatbots with Langchain 0.3
Langchain explores conversational memory in chatbots, covering core components and memory types like buffer and summary memory. They transition to a modern approach, "runnable with message history," ensuring seamless integration of chat history for enhanced conversational experiences.

Mastering AI Prompts: Lang Chain's Guide to Optimal Model Performance
Lang Chain explores the crucial role of prompts in AI models, guiding users through the process of structuring effective prompts and invoking models for optimal performance. The video also touches on future prompting for smaller models, enhancing adaptability and efficiency.

Enhancing AI Observability with Langmith and Linesmith
Langmith, part of Lang Chain, offers AI observability for LMS and agents. Linesmith simplifies setup, tracks activities, and provides valuable insights with minimal effort. Obtain an API key for access to tracing projects and detailed information. Enhance observability by making functions traceable and utilizing filtering options in Linesmith.