Exploring Google Gemini 2: Advancements in AI Image Recognition

- Authors
- Published on
- Published on
In the thrilling world of AI advancements, Google's Gemini 2 model has emerged as a potential game-changer, challenging the dominance of OpenAI. This cutting-edge model is laser-focused on the agent use case, showcasing a remarkable ability to produce structured output with precision. The team behind the scenes is diving deep into the realms of text to image and image to text modalities, pushing the boundaries of what AI technology can achieve. With more Gemini 2 examples on the horizon, the excitement is palpable as they explore the model's capabilities on complex and challenging images, uncovering its strengths and areas for improvement.
Harnessing the power of Google AI Studio API key, the team embarks on a journey of experimentation with Gemini 2 Flash, emphasizing its experimental nature and the need for cautious exploration. By strategically setting system prompts and safe settings, they guide the model to provide accurate and detailed descriptions of images, revealing its prowess in image recognition. Gemini 2's unique ability to output markdown format descriptions showcases its knack for identifying various elements within images, setting it apart in the realm of AI technology.
Through meticulous fine-tuning of prompts and parameters, the team delves into the nuances of Gemini 2's performance, constantly seeking ways to enhance its object identification capabilities. By drawing bounding boxes to visually represent the model's outputs, they paint a vivid picture of Gemini 2's accuracy in recognizing objects within images. As they navigate the complexities of AI technology, the team remains dedicated to optimizing Gemini 2's potential, pushing the boundaries of what this groundbreaking model can achieve in the realm of image recognition tasks.

Image copyright Youtube
Image copyright Youtube
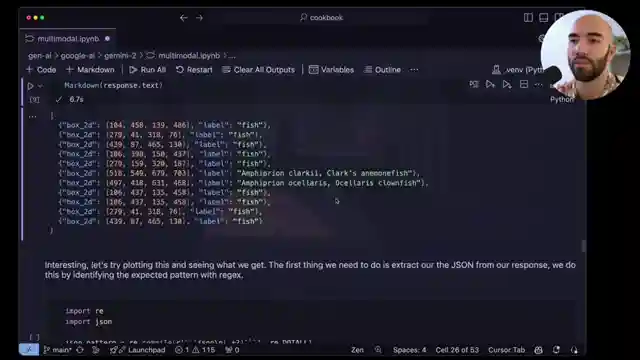
Image copyright Youtube
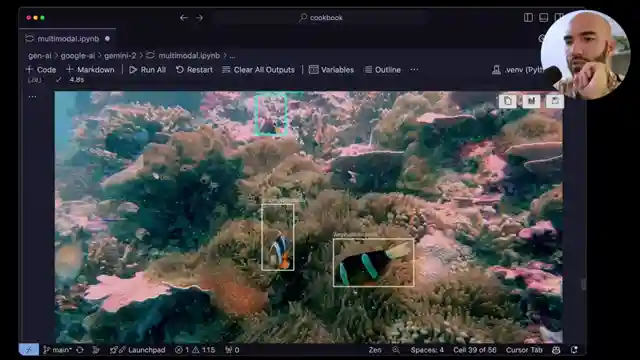
Image copyright Youtube
Watch Gemini 2 Multimodal and Spatial Awareness in Python on Youtube
Viewer Reactions for Gemini 2 Multimodal and Spatial Awareness in Python
AI workflows opportunities
Comparison with other models like Florence2 and Qwen 2VL
Concerns about non-open source models for enterprise use
Overview of Google's Gemini 2 Model and its Multimodal Capabilities
Focus on Agents in Gemini 2
Running the Code locally and in Google Colab
Describing Images accurately and inaccuracies with corals
Image Bounding Boxes generation and improvements
Examples of correct identifications in complex scenes
Comparison between Google Gemini and OpenAI GPTs
Related Articles

Exploring AI Agents and Tools in Lang Chain: A Deep Dive
Lang Chain explores AI agents and tools, crucial for enhancing language models. The video showcases creating tools, agent construction, and parallel tool execution, offering insights into the intricate world of AI development.

Mastering Conversational Memory in Chatbots with Langchain 0.3
Langchain explores conversational memory in chatbots, covering core components and memory types like buffer and summary memory. They transition to a modern approach, "runnable with message history," ensuring seamless integration of chat history for enhanced conversational experiences.

Mastering AI Prompts: Lang Chain's Guide to Optimal Model Performance
Lang Chain explores the crucial role of prompts in AI models, guiding users through the process of structuring effective prompts and invoking models for optimal performance. The video also touches on future prompting for smaller models, enhancing adaptability and efficiency.

Enhancing AI Observability with Langmith and Linesmith
Langmith, part of Lang Chain, offers AI observability for LMS and agents. Linesmith simplifies setup, tracks activities, and provides valuable insights with minimal effort. Obtain an API key for access to tracing projects and detailed information. Enhance observability by making functions traceable and utilizing filtering options in Linesmith.