Unleashing Longnet: Revolutionizing Large Language Models

- Authors
- Published on
- Published on
Today on sentdex, we delve into the world of large language models and their struggle with limited context lengths. These models, like the popular GPT series, are hitting a wall with a maximum of around 2048 tokens, restricting their ability to handle complex tasks beyond simple prompts. Even with some models offering larger contexts, issues with GPU memory, processing time, and model quality persist, leaving users yearning for more.
Enter Microsoft's longnet, a potential game-changer in the realm of large language models. With claims of accommodating up to a billion tokens, longnet proposes dilated attention to tackle the challenges of memory and processing speed. While it shows promise in addressing some of the existing issues, questions linger regarding its comparison to traditional Transformers and the quality of dilated attention over extensive token counts.
The quest for a breakthrough in attention mechanisms becomes paramount as the demand for larger context windows in Transformer-based models intensifies. Despite the allure of billion-token capacities, concerns loom over the practicality and effectiveness of such vast contexts. The future of large language models hinges on the ability to revolutionize attention mechanisms to unlock the full potential of expansive context windows.

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube
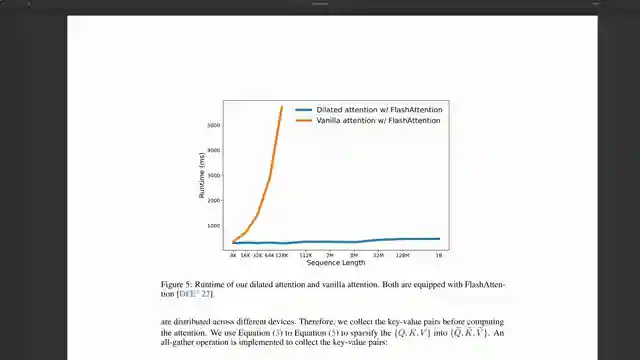
Image copyright Youtube
Watch Better Attention is All You Need on Youtube
Viewer Reactions for Better Attention is All You Need
Authors of the original Attention Is All You Need paper have left Google
Parallels to human cognition in attention mechanisms
ChatGPT responses can be mind-blowing and infuriating
The need for stateful LLMs and managing context
Exploring the complexity of attention in transformers
Potential breakthroughs in LLM architecture
Challenges in scaling context size
Liquid neural networks and lack of repositories
Comparisons between AI issues and Operating Systems design
Emulating attention at the hardware level
Related Articles

Robotic Hand Control Innovations: Challenges and Solutions
Jeff the G1 demonstrates precise robotic hand control using a keyboard. Challenges with SDK limitations lead to innovative manual training methods for tasks like retrieving a $65,000 bottle of water. Improved features include faster walking speed and emergency stop function.

Enhanced Robotics: Jeff the G1's Software Upgrades and LiDAR Integration
sentdex showcases upgrades to Jeff the G1's software stack, including RGB cameras, lidar for 3D mapping, and challenges with camera positioning and Ethernet connectivity. Embracing simplicity with Kiss ICP and Open3D, they navigate LiDAR integration for enhanced robotic exploration.

Unitry G1 Edu Ultimate B Review: Features, Pricing, and Development Potential
Explore the Unitry G1 edu Ultimate B humanoid robot in this in-depth review by sentdex. Discover its features, pricing, and development potential.

Unlocking Vibe Coding: Robot Hand Gestures and Version Control Explained
Explore the world of Vibe coding with sentdex as they push the boundaries of programming using language models. Discover the intricacies of robotic hand gestures and the importance of version control in this engaging tech journey.