Unleashing Chatterbox TTS: Voice Cloning & Emotion Control Revolution

- Authors
- Published on
- Published on
In this exhilarating journey through the world of cutting-edge TTS technology, the team at Resemble AI unveils the Chatterbox model, a true game-changer in the realm of voice cloning and emotion control. With a modest 500 million parameters, this open-source marvel stands tall against its larger counterparts, offering users the power to clone voices with just a snippet of reference audio. The Chatterbox model's ability to infuse emotion into generated text sets it apart from the competition, allowing for a truly personalized and dynamic user experience.
As the team delves deeper into the capabilities of Chatterbox, they demonstrate its seamless integration with platforms like Hugging Face, providing users with a user-friendly experience. By leveraging 500,000 hours of clean training data, the model ensures optimal performance and quality output. The ability to watermark generated audio adds a layer of authenticity verification, giving users peace of mind in a world where deepfakes abound.
Comparisons with industry giants like 11 Labs highlight Chatterbox's unique selling points, particularly its preference in voice quality. The model's voice cloning feature shines through as it effortlessly mimics voices like that of Zuckerberg, showcasing its versatility and potential for creative applications. With the Chatterbox TTS extended repo offering enhanced functionalities for processing text files and output formats, users are empowered to explore new horizons in audio content creation.
In conclusion, the Chatterbox model emerges as a beacon of innovation, offering a perfect balance of control, privacy, and performance. Its adaptability and ease of use make it a compelling choice for creators seeking a customizable and reliable TTS solution. As the team bids farewell, viewers are left with a sense of excitement and anticipation for the endless possibilities that Chatterbox brings to the table in the ever-evolving landscape of audio technology.

Image copyright Youtube
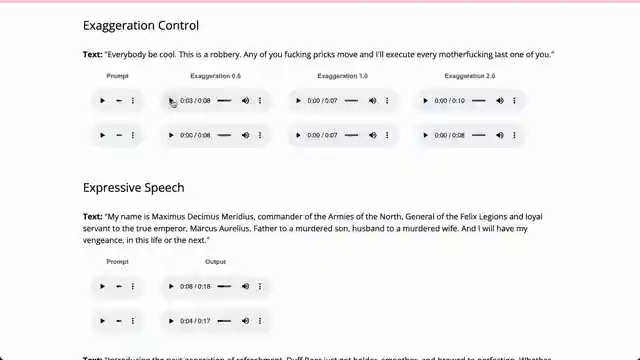
Image copyright Youtube
Image copyright Youtube
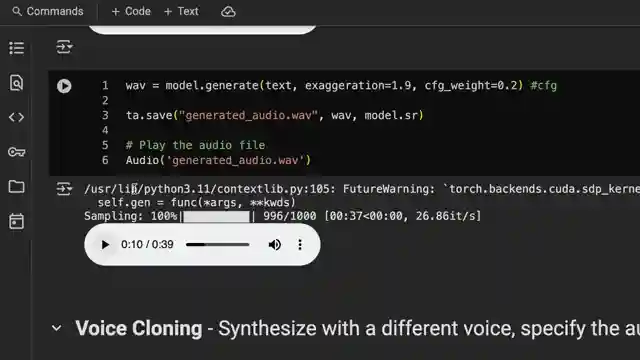
Image copyright Youtube
Watch Building with Chatterbox TTS, Voice Cloning & Watermarking on Youtube
Viewer Reactions for Building with Chatterbox TTS, Voice Cloning & Watermarking
Observations made about specific moments in the video, such as at 10:13 and 12:37
Interest in a potential collaboration between Chatterbox and Kokoro for voice cloning
Appreciation for the content creator
Inquiry about the languages supported by the technology
Concerns about how accents are retained in the generated voices
Experimenting with the exaggeration option for TTS dirty talk
Questions about the hardware requirements, specifically if it can run on an M1 MacBook Pro
Comparison between Chatterbox and Index TTS 1.5
Related Articles

Unleashing Gemini CLI: Google's Free AI Coding Tool
Discover the Gemini CLI by Google and the Gemini team. This free tool offers 60 requests per minute and 1,000 requests per day, empowering users with AI-assisted coding capabilities. Explore its features, from grounding prompts in Google Search to using various MCPS for seamless project management.

Nanet's OCR Small: Advanced Features for Specialized Document Processing
Nanet's OCR Small, based on Quen 2.5VL, offers advanced features like equation recognition, signature detection, and table extraction. This model excels in specialized OCR tasks, showcasing superior performance and versatility in document processing.

Revolutionizing Language Processing: Quen's Flexible Text Embeddings
Quen introduces cutting-edge text embeddings on HuggingFace, offering flexibility and customization. Ranging from 6B to 8B in size, these models excel in benchmarks and support instruction-based embeddings and reranking. Accessible for local or cloud use, Quen's models pave the way for efficient and dynamic language processing.
Unleashing Chatterbox TTS: Voice Cloning & Emotion Control Revolution
Discover Resemble AI's Chatterbox TTS model, revolutionizing voice cloning and emotion control with 500M parameters. Easily clone voices, adjust emotion levels, and verify authenticity with watermarks. A versatile and user-friendly tool for personalized audio content creation.