Step Fun Unveils State-of-the-Art Text-to-Video and Speech-to-Speech Models

- Authors
- Published on
- Published on
In this riveting episode from 1littlecoder, we delve into the groundbreaking world of Step Fun, a mysterious company hailing all the way from China. They've unleashed a duo of cutting-edge models that are causing quite a stir in the tech realm. First up, we have the text-to-video marvel, Step Video T2V, boasting a whopping 30 billion parameters and the ability to churn out a mind-boggling 200 frames per second. This beast demands a hefty 80 GB of GPU memory to flex its computational muscles and deliver jaw-dropping visuals.
But that's not all - Step Fun doesn't stop there. They've also rolled out a voice chat sensation, Step Audio Chat, a speech-to-speech powerhouse with a colossal 130 billion parameters. To run this behemoth, you'd better buckle up with a whopping 265 GB of GPU memory. The folks at Step Fun are clearly not messing around when it comes to pushing the boundaries of audio and video technology.
As we witness the samples on their website, it's evident that Step Fun's models are not your run-of-the-mill creations. The video quality is nothing short of impressive, showcasing a level of detail and realism that leaves you in awe. And let's not forget about the turbo version for those who need speed over everything else - a nifty option for those in a hurry to generate their visual masterpieces. With Step Fun's models available for download on Hugging Face, the possibilities for creators and tech enthusiasts are expanding at an exponential rate.
Step Fun's ambitious mission to scale up possibilities for all is clearly reflected in the caliber of their models. The future looks bright for this enigmatic company as they hint at even more groundbreaking releases on the horizon. So, buckle up, folks, because Step Fun is here to shake up the audio and video landscape like never before.

Image copyright Youtube
Image copyright Youtube
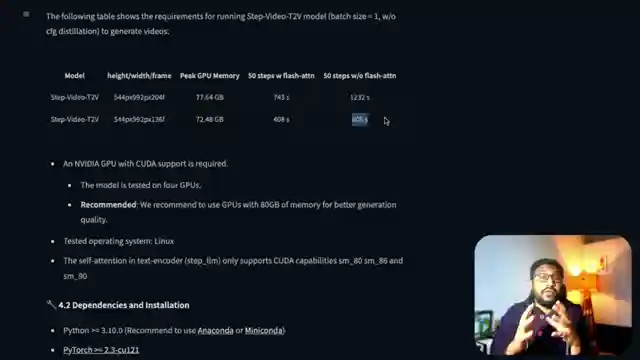
Image copyright Youtube
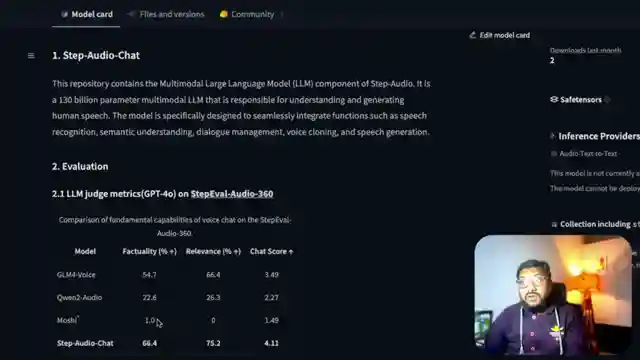
Image copyright Youtube
Watch The NEXT Deepseek? Meet StepFun AI from China! on Youtube
Viewer Reactions for The NEXT Deepseek? Meet StepFun AI from China!
China's contribution to open source AI
Speculation on the Step Function logo
Excitement about advancements in video models from China
Concerns about using Chinese models due to potential legal issues
Interest in AI models like OpenThinker-32B and Huginn-3.5B
Comparison to other AI models like GLM-4
Jokes about the name "StepFun"
Interest in TTS technology
Mention of GPU
Humorous comment about the name sounding like a cheap movie title
Related Articles

Revolutionizing Music Creation: Google's Magenta Real Time Model
Discover Magenta, a cutting-edge music generation model from Google deep mind. With 800 million parameters, Magenta offers real-time music creation on Google Collab TPU. Available on Hugging Face, this AI innovation is revolutionizing music production.

Nanits OCRS Model: Free Optical Character Recognition Tool Outshines Competition
Discover Nanits' OCRS model, a powerful optical character recognition tool fine-tuned from Quinn 2.5 VLM. This free model outshines Mistral AI's paid OCR API, excelling in latex equation recognition, image description, signature detection, and watermark extraction. Accessible via Google Collab, it offers seamless conversion of documents to markdown format. Experience the future of OCR technology with Nanits.

Revolutionizing Voice Technology: Chatterbox by Resemble EI
Resemble EI's Chatterbox, a half-billion parameter model licensed under MIT, excels in text-to-speech and voice cloning. Users can adjust parameters like pace and exaggeration for customized output. The model outperforms competitors, making it ideal for diverse voice applications. Subscribe to 1littlecoder for more insights.

Unlock Productivity: Google AI Studio's Branching Feature Revealed
Discover the hidden Google AI studio feature called branching on 1littlecoder. This revolutionary tool allows users to create different conversation timelines, boosting productivity and enabling flexible communication. Branching is a game-changer for saving time and enhancing learning experiences.