Microsoft's F4 and 54 Models: Revolutionizing AI with Multimodal Capabilities

- Authors
- Published on
- Published on
In a groundbreaking move, Microsoft unveiled the F4 model with a whopping 14 billion parameters back in December. The tech world was abuzz with excitement, but the weights for this beast were shrouded in mystery until January. Ah, the anticipation! But hold on a minute, folks. What about the real star of the show, the 3.8 billion parameter mini model that had tongues wagging in the tech community? Well, fear not, because Microsoft finally dropped the mic and delivered the goods on that front, along with a range of other model varieties to spice things up.
Now, let's talk about what makes these models tick. The 54 mini instruct model has got a nifty new feature - function calling. Perfect for those local model tasks that require a touch of finesse without the heavy lifting. And let's not forget, Microsoft isn't living in the clouds - they know you want these models on your devices. That's why they've rolled out the Onyx runtime, making it possible to flex these models on platforms like Raspberry Pi and mobile phones. It's a game-changer, folks.
But wait, there's more! The 54 multimodal model is where things get really spicy. With a vision encoder and an audio encoder in the mix, this bad boy can process images and audio like a pro. And let's not overlook the sheer scale of this operation - we're talking 3.8 billion parameters here, folks. This model is a beast in every sense of the word. The Transformers library has leveled up to handle these multimodal marvels, making it a breeze to process text, images, and audio data with finesse. And the cherry on top? The model's prowess in tasks like OCR and translation is nothing short of jaw-dropping.

Image copyright Youtube

Image copyright Youtube
Image copyright Youtube
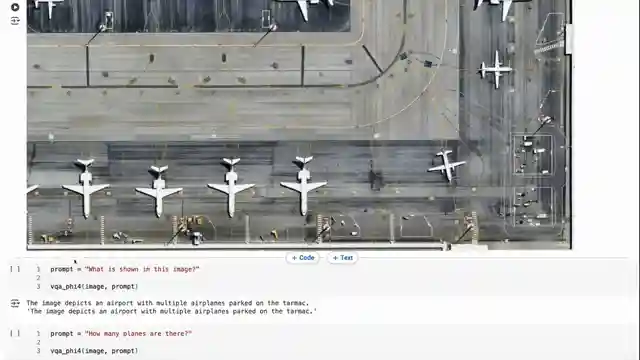
Image copyright Youtube
Watch Unlock Open Multimodality with Phi-4 on Youtube
Viewer Reactions for Unlock Open Multimodality with Phi-4
phi4 model is favored for general purpose offline usage
Excitement for the new llama4 model
Request for a local tool calling video with the model
Question about audio input triggering a function call
Appreciation for the video content
Mention of light mode on Jupyter
Ollama 0.5.12 current build doesn't support mini or multimodal version
Phi model has been used locally and is considered fantastic, but lacks function calling support
Mention of being the first to comment
Mention of being the third to comment
Related Articles

Unleashing Gemini CLI: Google's Free AI Coding Tool
Discover the Gemini CLI by Google and the Gemini team. This free tool offers 60 requests per minute and 1,000 requests per day, empowering users with AI-assisted coding capabilities. Explore its features, from grounding prompts in Google Search to using various MCPS for seamless project management.

Nanet's OCR Small: Advanced Features for Specialized Document Processing
Nanet's OCR Small, based on Quen 2.5VL, offers advanced features like equation recognition, signature detection, and table extraction. This model excels in specialized OCR tasks, showcasing superior performance and versatility in document processing.

Revolutionizing Language Processing: Quen's Flexible Text Embeddings
Quen introduces cutting-edge text embeddings on HuggingFace, offering flexibility and customization. Ranging from 6B to 8B in size, these models excel in benchmarks and support instruction-based embeddings and reranking. Accessible for local or cloud use, Quen's models pave the way for efficient and dynamic language processing.

Unleashing Chatterbox TTS: Voice Cloning & Emotion Control Revolution
Discover Resemble AI's Chatterbox TTS model, revolutionizing voice cloning and emotion control with 500M parameters. Easily clone voices, adjust emotion levels, and verify authenticity with watermarks. A versatile and user-friendly tool for personalized audio content creation.