Mastering OCR: MRA's Multilingual Model Unleashed

- Authors
- Published on
- Published on
Today on the channel, we dive into the world of OCR models with MRA's latest release, setting the stage for a showdown with competitors like om OCR and Gemini. MRA's model, accessed through their API, boasts a unique feature set that includes text and image extraction, even converting tables to markdown for seamless processing. This powerhouse can handle a variety of inputs, from images to full PDFs, making it a versatile tool for tasks like rag and visual question answering. With a price tag of $1 per thousand pages, the model offers cost-effective solutions, doubling for batch inference for those looking to scale up their operations.
MRA's OCR model shines in its multilingual and multimodal capabilities, showcasing prowess in languages like Hindi and Arabic, outperforming competitors across the board. The model's on-prem processing power, handling up to 2,000 pages per minute on a single node, makes it an attractive option for companies with privacy concerns or data sensitivity. The structured JSON outputs provided by the model open up possibilities for further processing and integration into various workflows, adding a layer of flexibility and customization to the mix.
In a thrilling code demonstration, the channel takes us through a hands-on experience with MRA's OCR API, showcasing its ease of use and efficiency in extracting text and images from various file formats. The demonstration highlights the model's ability to handle different languages, such as Thai, with impressive accuracy and structured output. The batch inference feature is explored, offering a cost-effective solution for processing large volumes of data. Overall, MRA's OCR API emerges as a valuable tool in the OCR landscape, providing users with a reliable, efficient, and customizable solution for their information extraction needs.

Image copyright Youtube
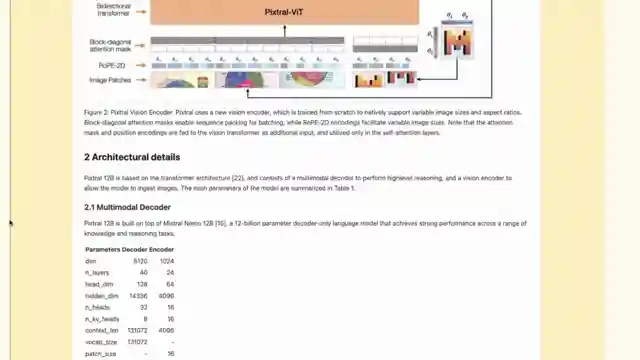
Image copyright Youtube
Image copyright Youtube
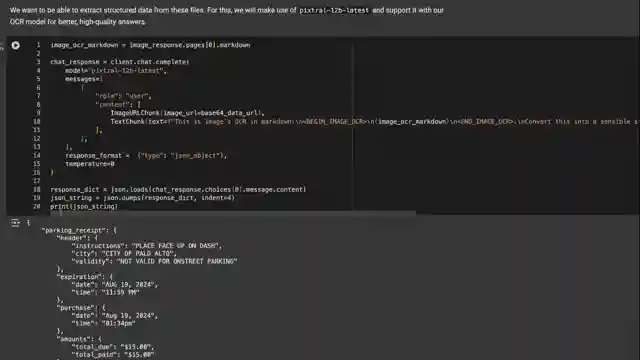
Image copyright Youtube
Watch Mistral OCR - Multimodal & Multilingual OCR on Youtube
Viewer Reactions for Mistral OCR - Multimodal & Multilingual OCR
Use cases for company processes with legal Arabic documents
Concerns about sharing data with another AI company through API
Comparison with Google OCR for unstructured/handwritten content
Testing with handwriting and accuracy of bounding boxes
Interest in building a graph database system with Mistral OCR
Preference for OCR and data extraction tasks using Gemini 2.0
Challenges with OCR in languages like Arabic
Requests for open-source OCR/document parser recommendations
Questions about handling handwriting and medieval words in OCR
Comparison with AllenAI OlmOCR and Gemini 2.0 Flash
Related Articles

Unleashing Gemini CLI: Google's Free AI Coding Tool
Discover the Gemini CLI by Google and the Gemini team. This free tool offers 60 requests per minute and 1,000 requests per day, empowering users with AI-assisted coding capabilities. Explore its features, from grounding prompts in Google Search to using various MCPS for seamless project management.

Nanet's OCR Small: Advanced Features for Specialized Document Processing
Nanet's OCR Small, based on Quen 2.5VL, offers advanced features like equation recognition, signature detection, and table extraction. This model excels in specialized OCR tasks, showcasing superior performance and versatility in document processing.

Revolutionizing Language Processing: Quen's Flexible Text Embeddings
Quen introduces cutting-edge text embeddings on HuggingFace, offering flexibility and customization. Ranging from 6B to 8B in size, these models excel in benchmarks and support instruction-based embeddings and reranking. Accessible for local or cloud use, Quen's models pave the way for efficient and dynamic language processing.

Unleashing Chatterbox TTS: Voice Cloning & Emotion Control Revolution
Discover Resemble AI's Chatterbox TTS model, revolutionizing voice cloning and emotion control with 500M parameters. Easily clone voices, adjust emotion levels, and verify authenticity with watermarks. A versatile and user-friendly tool for personalized audio content creation.