Enhancing Language Models: Slow Thinking with Monte Carlo Tree Search

- Authors
- Published on
- Published on
Today on 1littlecoder, the team delves into the intriguing world of enhancing large language models with the revolutionary concept of slow thinking. Inspired by the human brain's system one and system two processes, they explore the paper "C8 Code: Chain of Associated Thoughts," which introduces a framework to enable LLMS to engage in deliberate, methodical decision-making. By incorporating Monte Carlo Tree Search (MCTS), the team aims to revolutionize the way LLMS approach problem-solving, mimicking the intricate processes of human thought.
The discussion centers around the framework's ability to dynamically pull in relevant information during reasoning, akin to how humans connect ideas to form coherent conclusions. Through a delicate balance of exploration and exploitation, the model navigates through various reasoning paths, ensuring a comprehensive exploration of solutions while avoiding repetitive or narrow answers. This innovative approach not only promises better accuracy and diverse solution exploration but also introduces adaptability by providing real-time information through associative memories.
Experimental results on datasets like Lang Chain, Hotpot, and Wiki Multi Hotot showcase the framework's effectiveness in generating more comprehensive and accurate responses compared to traditional models. The qualitative output further highlights the model's enhanced performance when utilizing the Chain of Associated Thoughts framework, underlining the potential for further advancements in this exciting field. With a focus on refining the model's internal reasoning processes and leveraging associative memories, the team sets the stage for a new era in large language model development, sparking curiosity and anticipation for future innovations in this space.

Image copyright Youtube

Image copyright Youtube
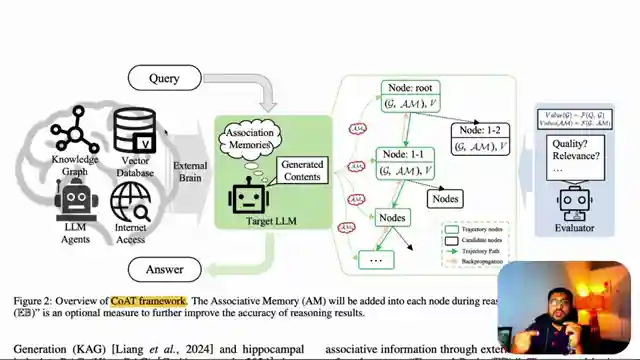
Image copyright Youtube
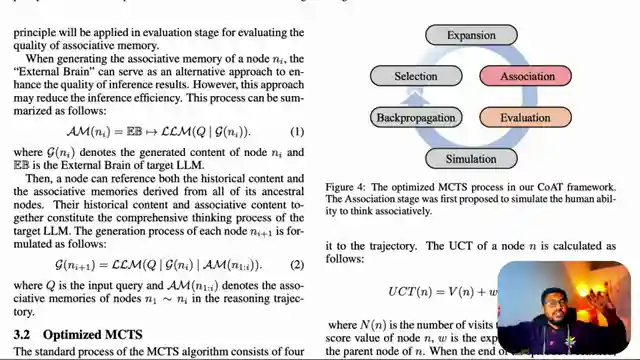
Image copyright Youtube
Watch Chain of Thoughts Upgraded, CoAT! on Youtube
Viewer Reactions for Chain of Thoughts Upgraded, CoAT!
Comment praising the paper reviews and lighting setup
Discussion on whether the process can be considered a multi-step LLM calls
Mention of GraphRAG with MCTS and use of tools in training models
Suggestion for color correction in the video
Inquiry about the software used for screen recording, voice recording, and webcam
Comment on the video creator's appearance resembling Trump due to the orange color
Request for help on fine-tuning DeepSeek - v3 base model using Google Colab
Discussion on System 1 and System 2 thinking in AI models
Thoughts on AI companies rebranding workflow time as thinking
Speculation on whether GPT-4o genuinely "thinks" or uses workflow orchestration
Related Articles

Revolutionizing Music Creation: Google's Magenta Real Time Model
Discover Magenta, a cutting-edge music generation model from Google deep mind. With 800 million parameters, Magenta offers real-time music creation on Google Collab TPU. Available on Hugging Face, this AI innovation is revolutionizing music production.

Nanits OCRS Model: Free Optical Character Recognition Tool Outshines Competition
Discover Nanits' OCRS model, a powerful optical character recognition tool fine-tuned from Quinn 2.5 VLM. This free model outshines Mistral AI's paid OCR API, excelling in latex equation recognition, image description, signature detection, and watermark extraction. Accessible via Google Collab, it offers seamless conversion of documents to markdown format. Experience the future of OCR technology with Nanits.

Revolutionizing Voice Technology: Chatterbox by Resemble EI
Resemble EI's Chatterbox, a half-billion parameter model licensed under MIT, excels in text-to-speech and voice cloning. Users can adjust parameters like pace and exaggeration for customized output. The model outperforms competitors, making it ideal for diverse voice applications. Subscribe to 1littlecoder for more insights.

Unlock Productivity: Google AI Studio's Branching Feature Revealed
Discover the hidden Google AI studio feature called branching on 1littlecoder. This revolutionary tool allows users to create different conversation timelines, boosting productivity and enabling flexible communication. Branching is a game-changer for saving time and enhancing learning experiences.