Deep Seek VL2: Efficient Vision Language Model with Superior Performance

- Authors
- Published on
- Published on
Deep Seek VL2, the latest creation from the brilliant minds at Deep Seek, is a vision language model that's causing quite a stir in the AI world. This model, available in three versions - Small, Tiny, and the standard VL2 - is all about efficiency. Thanks to its Mixture of Experts concept, only specific parameters are activated during each token, making it a computational powerhouse. And let me tell you, when it comes to performance, this bad boy doesn't disappoint. With benchmarks like MM Bench and Math Vista under its belt, Deep Seek VL2 Tiny is giving larger models a run for their money.
But that's not all. Unlike some other models out there, Deep Seek VL2 is a proper vision language model, with distinct vision and language components. It's like having the best of both worlds in one sleek package. And let me tell you, the architecture behind this beauty is a sight to behold. From the dynamic tiling process to the vision language adapter, every component works seamlessly to deliver top-notch results. And when it comes to OCR, Deep Seek VL2 is a true champion. With impressive scores in benchmarks like DocVQA, this model is setting new standards in optical character recognition.
And let's not forget about its meme understanding capabilities. Yes, you heard that right. This model can dissect memes with the precision of a seasoned comedian. From capturing the playful defiance of childhood to decoding the struggles of a PhD student, Deep Seek VL2 is a meme maestro. And when it comes to multi-image conversations, this model shines like a beacon in the night. Whether you're planning a meal based on ingredients in your fridge or seeking the perfect drink pairing, Deep Seek VL2 has got you covered. And the best part? It's bilingual, so you can converse with it in English or Chinese without missing a beat.
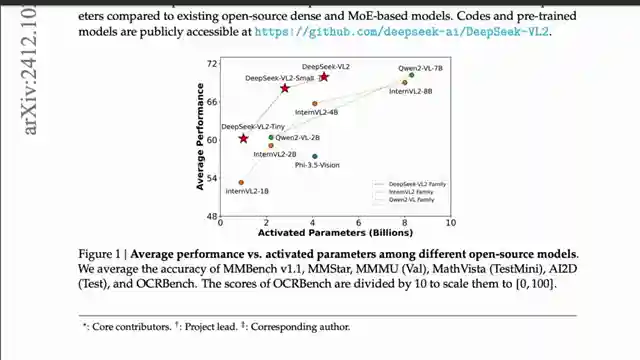
Image copyright Youtube
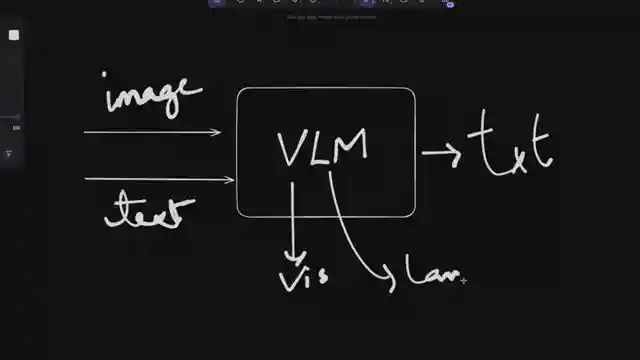
Image copyright Youtube
Image copyright Youtube
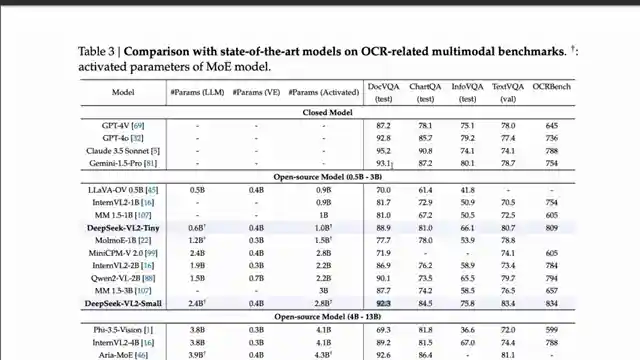
Image copyright Youtube
Watch Deepseek is back with VISION on Youtube
Viewer Reactions for Deepseek is back with VISION
Positive feedback on the video performance and content
Requests for practical implementation of DeepSeek VL model and a tutorial
Suggestions for more hands-on demonstrations using different tools and models
Interest in running VL models locally and on edge devices
Question about running the model with videos
Request for a tutorial on how to become a professional programmer in artificial intelligence
Comparison between different versions of the model
Difficulty in using visual models due to installation and usability challenges
Specific requests for tutorials on running the model and using it for OCR in various languages
Criticism of the thumbnail image quality
Related Articles

Revolutionizing Music Creation: Google's Magenta Real Time Model
Discover Magenta, a cutting-edge music generation model from Google deep mind. With 800 million parameters, Magenta offers real-time music creation on Google Collab TPU. Available on Hugging Face, this AI innovation is revolutionizing music production.

Nanits OCRS Model: Free Optical Character Recognition Tool Outshines Competition
Discover Nanits' OCRS model, a powerful optical character recognition tool fine-tuned from Quinn 2.5 VLM. This free model outshines Mistral AI's paid OCR API, excelling in latex equation recognition, image description, signature detection, and watermark extraction. Accessible via Google Collab, it offers seamless conversion of documents to markdown format. Experience the future of OCR technology with Nanits.

Revolutionizing Voice Technology: Chatterbox by Resemble EI
Resemble EI's Chatterbox, a half-billion parameter model licensed under MIT, excels in text-to-speech and voice cloning. Users can adjust parameters like pace and exaggeration for customized output. The model outperforms competitors, making it ideal for diverse voice applications. Subscribe to 1littlecoder for more insights.

Unlock Productivity: Google AI Studio's Branching Feature Revealed
Discover the hidden Google AI studio feature called branching on 1littlecoder. This revolutionary tool allows users to create different conversation timelines, boosting productivity and enabling flexible communication. Branching is a game-changer for saving time and enhancing learning experiences.