Dier: Innovative TTS System by Toby and Jay at Nari Labs

- Authors
- Published on
- Published on
In the realm of cutting-edge technology, a duo of ambitious undergraduates, Toby and Jay, have unleashed a groundbreaking TTS system known as Dier. This 1.6 billion parameter marvel, birthed under the banner of Nari Labs, stands tall among industry giants like L1 Labs with its exceptional quality and control over scripts and voices. Drawing inspiration from the likes of Soundstorm and Parakeet, these young innovators faced the daunting challenge of compute power, ultimately harnessing Google's TPU research cloud grants to fuel their creation.
Dier, now available on GitHub and Hugging Face, offers enthusiasts a playground for text synthesis and voice cloning, promising an experience akin to the acclaimed Notebook LM podcast. However, the road to perfection was not without its bumps, as the team grappled with issues like audio speed and voice variation. Through clever segmentation of scripts and tinkering with audio speed using tools like librosa and rubber band, they managed to elevate the output quality, albeit with some quirks along the way.
The model's use of classifier-free guidance plays a pivotal role in dictating audio speed, leading to innovative solutions like generating short audios for optimal results. Future plans include integrating Dier into the MLX audio library, expanding its reach and usability. While real-time applications may be a stretch, Dier's forte lies in crafting top-tier audio tailored for podcast-style content. Enthusiasts are urged to dive into the code, experiment with the system, and provide valuable feedback on its performance compared to established players like Kokuro.
Image copyright Youtube
Image copyright Youtube
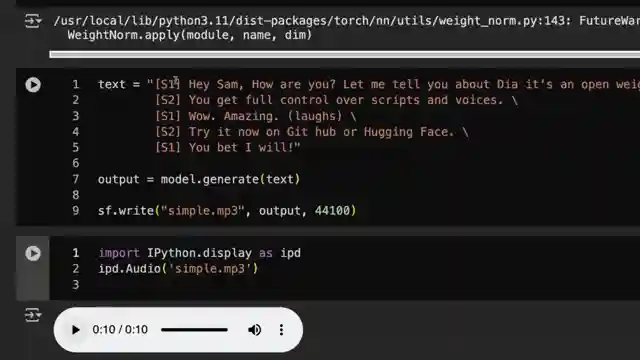
Image copyright Youtube
Image copyright Youtube
Watch Dia 1.6B TTS for NotebookLM Podcasts on Youtube
Viewer Reactions for Dia 1.6B TTS for NotebookLM Podcasts
Voice cloning is a popular topic of interest
Users are curious about fine-tuning the model for other languages
Some users are interested in the technical specifications for running the model
Comparison with other models like Kokoro is mentioned
Questions about audio stitching and maintaining consistent voices
Users are discussing the use of different TTS models for voice alternation
Some users express concerns about voice cloning and transitioning from Jax to Pytorch
Comparison with Google's unreleased TTS model is brought up
Users are impressed by the capabilities of the model and aspire to reach similar levels
Some users express jealousy over the model's development timeline and their own programming experience.
Related Articles

Unleashing Gemini CLI: Google's Free AI Coding Tool
Discover the Gemini CLI by Google and the Gemini team. This free tool offers 60 requests per minute and 1,000 requests per day, empowering users with AI-assisted coding capabilities. Explore its features, from grounding prompts in Google Search to using various MCPS for seamless project management.

Nanet's OCR Small: Advanced Features for Specialized Document Processing
Nanet's OCR Small, based on Quen 2.5VL, offers advanced features like equation recognition, signature detection, and table extraction. This model excels in specialized OCR tasks, showcasing superior performance and versatility in document processing.

Revolutionizing Language Processing: Quen's Flexible Text Embeddings
Quen introduces cutting-edge text embeddings on HuggingFace, offering flexibility and customization. Ranging from 6B to 8B in size, these models excel in benchmarks and support instruction-based embeddings and reranking. Accessible for local or cloud use, Quen's models pave the way for efficient and dynamic language processing.

Unleashing Chatterbox TTS: Voice Cloning & Emotion Control Revolution
Discover Resemble AI's Chatterbox TTS model, revolutionizing voice cloning and emotion control with 500M parameters. Easily clone voices, adjust emotion levels, and verify authenticity with watermarks. A versatile and user-friendly tool for personalized audio content creation.