Unveiling Solo Bench: AI Language Models Face Surprising Challenges

- Authors
- Published on
- Published on
In a world where language models reign supreme, a new challenger emerges: solo bench. This benchmark, devised by the ingenious minds at 1littlecoder, dares to test the very limits of these AI behemoths. Picture this - 250 sentences, each a unique masterpiece following a strict verb-adjective-noun-noun structure. Sounds simple, right? Wrong. The catch? No repeating words, no external tools, just pure linguistic prowess. It's like asking a race car to navigate a minefield blindfolded - treacherous yet thrilling.
As the dust settles, the results are in. Gemini 2.5 Pro leads the pack with a commendable 75%, leaving competitors like O3 and Deepseek R1 in its digital dust. But here's the kicker - even the mightiest models struggle to crack the code, with some barely scraping past 20%. It's a David and Goliath tale, with the underdog benchmark exposing the Achilles' heel of these AI giants. The stage is set, the challenge clear - follow the rules, no shortcuts allowed. Can the language models rise to the occasion, or will they stumble at the final hurdle?
Enter the arena of solo bench, where the rules are simple yet the task herculean. This benchmark isn't just a test; it's a statement - a bold declaration that complexity doesn't always equal success. The team at 1littlecoder has thrown down the gauntlet, inviting all comers to take a shot at glory. And as the models grapple with the linguistic puzzle laid before them, one thing becomes abundantly clear - in the world of AI, nothing is ever as straightforward as it seems. So, buckle up, folks. The race is on, and the finish line is nowhere in sight.
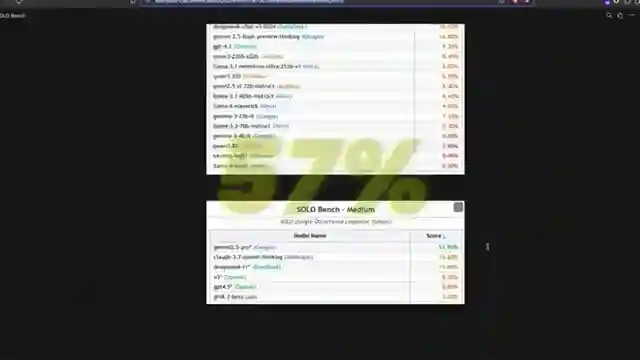
Image copyright Youtube
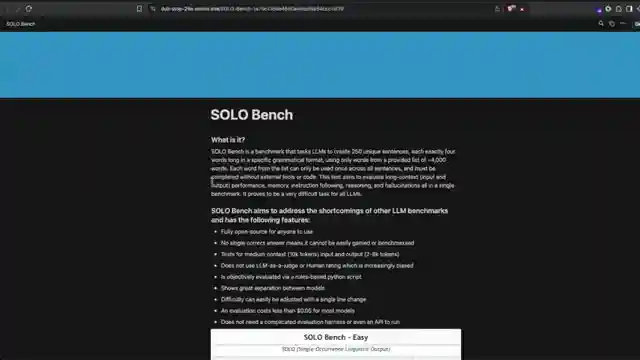
Image copyright Youtube
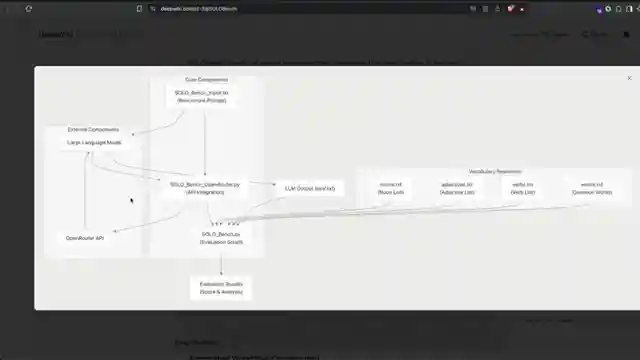
Image copyright Youtube
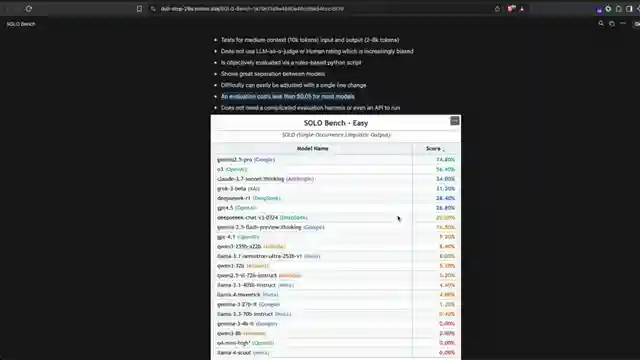
Image copyright Youtube
Watch Most LLMs are Bad at this Simple Benchmark Test! on Youtube
Viewer Reactions for Most LLMs are Bad at this Simple Benchmark Test!
Positive feedback on the objective benchmarks presented
Interest in more materials with benchmarks to assess AI trustworthiness
Surprise at Gemini's performance on a difficult test
Criticism of LLMs for struggling with basic math problems
Mention of LLMs' limitations in expressing numbers in different languages
Request for benchmarks testing real-world performance and payment completion rates for gig contracts on platforms like Fiverr
Emphasis on the importance of testing models on real-world tasks and tracking their success rates over time
Related Articles

Revolutionizing Music Creation: Google's Magenta Real Time Model
Discover Magenta, a cutting-edge music generation model from Google deep mind. With 800 million parameters, Magenta offers real-time music creation on Google Collab TPU. Available on Hugging Face, this AI innovation is revolutionizing music production.

Nanits OCRS Model: Free Optical Character Recognition Tool Outshines Competition
Discover Nanits' OCRS model, a powerful optical character recognition tool fine-tuned from Quinn 2.5 VLM. This free model outshines Mistral AI's paid OCR API, excelling in latex equation recognition, image description, signature detection, and watermark extraction. Accessible via Google Collab, it offers seamless conversion of documents to markdown format. Experience the future of OCR technology with Nanits.

Revolutionizing Voice Technology: Chatterbox by Resemble EI
Resemble EI's Chatterbox, a half-billion parameter model licensed under MIT, excels in text-to-speech and voice cloning. Users can adjust parameters like pace and exaggeration for customized output. The model outperforms competitors, making it ideal for diverse voice applications. Subscribe to 1littlecoder for more insights.

Unlock Productivity: Google AI Studio's Branching Feature Revealed
Discover the hidden Google AI studio feature called branching on 1littlecoder. This revolutionary tool allows users to create different conversation timelines, boosting productivity and enabling flexible communication. Branching is a game-changer for saving time and enhancing learning experiences.