Python PDF Table Extraction: Camelot vs. Tabula vs. PDF Plumber
- Authors
- Published on
- Published on
In this exhilarating exploration, the NeuralNine crew dives headfirst into the thrilling world of parsing tables from PDFs using Python. Buckle up as they pit Camelot, Tabula, PDF Plumber, and the unique LLM Whisperer against each other in a high-octane showdown. Camelot, the first contender, promises table extraction prowess but falters when faced with the intricate structure of PDFs, leaving the team yearning for more precision.
Next up is Tabula, a Java-based heavyweight in the ring. With its allure of multiple tables and lattice/stream extraction, Tabula seems like a formidable opponent. However, as the dust settles, it becomes evident that Tabula struggles to deliver the knockout blow, leaving the team searching for a more effective solution. Enter PDF Plumber, a precision-focused contender known for its accuracy and customizability.
With PDF Plumber in their corner, the team embarks on a quest for the ultimate table extraction solution. Armed with a slew of customizable settings, PDF Plumber manages to extract tables with more finesse, offering a glimmer of hope in the chaotic world of PDF parsing. But just when it seems like the battle is won, a wildcard enters the arena - LLM Whisperer. Sponsored by LLM Whisperer and Unra, this unconventional approach introduces a new dimension to the table extraction game.
LLM Whisperer, with its unique API key requirement, presents a tantalizing prospect for those seeking a cutting-edge solution. As the team delves into the realm of LLM Whisperer, the stakes are higher than ever. Will this underdog emerge victorious, or will the tried-and-tested contenders reign supreme? Only time will tell in this adrenaline-fueled quest for the ultimate PDF table extraction champion.
Image copyright Youtube
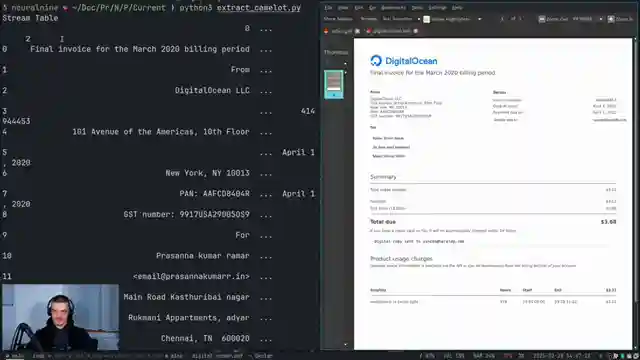
Image copyright Youtube
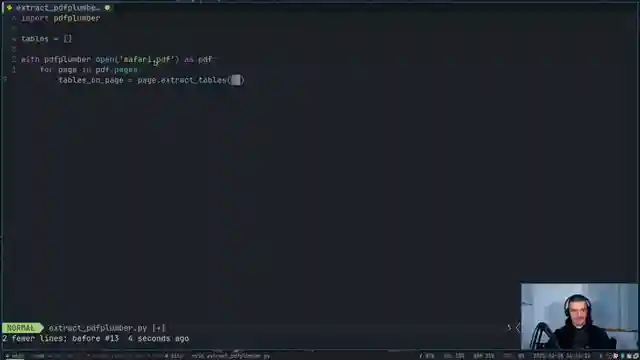
Image copyright Youtube
Image copyright Youtube
Watch Python Libraries to Extract Tables from PDFs on Youtube
Viewer Reactions for Python Libraries to Extract Tables from PDFs
Tabula (Java web app version) works best for extracting tables
Python-based PDF table extractors had unpredictable and inaccurate output
Docker was useful for running Tabula Java web app on Ubuntu 24.04
Suggestion for intro automation to show results before watching
Request for more complex table examples like financial statements
Mention of ML-based chips extracting data from invoices for 20 years
Recommendation for using chat GPT directly with pypdf
Request for a video on enlarging VRAM of GPU
Related Articles
Building Stock Prediction Tool: PyTorch, Fast API, React & Warp Tutorial
NeuralNine constructs a stock prediction tool using PyTorch, Fast API, React, and Warp. The tutorial showcases training the model, building the backend, and deploying the application with Docker. Witness the power of AI in predicting stock prices with this comprehensive guide.

Exploring Arch Linux: Customization, Updates, and Troubleshooting Tips
NeuralNine explores the switch to Arch Linux for cutting-edge updates and customization, detailing the manual setup process, troubleshooting tips, and the benefits of the Arch User Repository.
Master Application Monitoring: Prometheus & Graphfana Tutorial
Learn to monitor applications professionally using Prometheus and Graphfana in Python with NeuralNine. This tutorial guides you through setting up a Flask app, tracking metrics, handling exceptions, and visualizing data. Dive into the world of application monitoring with this comprehensive guide.

Mastering Logistic Regression: Python Implementation for Precise Class Predictions
NeuralNine explores logistic regression, a classification algorithm revealing probabilities for class indices. From parameters to sigmoid functions, dive into the mathematical depths for accurate predictions in Python.