Mastering PDF Chat: Extracting Images, Tables, and Text with GPT Models

- Authors
- Published on
- Published on
In this riveting video from Alejandro AO - Software & Ai, the team delves into the fascinating world of chatting with PDFs, uncovering the secrets of engaging with images, tables, and plots to extract valuable information. With the flair of a seasoned explorer, they demonstrate the art of querying a pipeline using a Google paper sample on attention, unraveling the mysteries hidden within the document. Through a visually captivating diagram, they guide viewers through the intricate process of parsing documents into distinct components like images, tables, and text, all while harnessing the power of a cutting-edge language model with multimodal input capabilities such as GPT 40 mini.
The team's meticulous approach involves summarizing elements using sophisticated language models, crafting concise summaries that encapsulate the essence of each component. By deftly tagging these summaries with a unique doc ID, they pave the way for seamless retrieval, linking the summarized data back to its original source. This meticulous linking process ensures that the summaries, once vectorized and loaded into a database, can be effortlessly retrieved based on user queries, forming the backbone of an efficient retrieval pipeline.
With a nod to the importance of doc ID metadata, the team underscores the critical role it plays in connecting the dots between summaries and their corresponding documents, enabling a streamlined retrieval process. Through their methodical approach, they showcase how querying a vector database can yield a treasure trove of relevant documents, complete with images, tables, and text, all primed and ready for generating insightful answers. As the video draws to a close, viewers are left on the edge of their seats, eagerly anticipating the upcoming code implementation that promises to bring this captivating journey full circle.
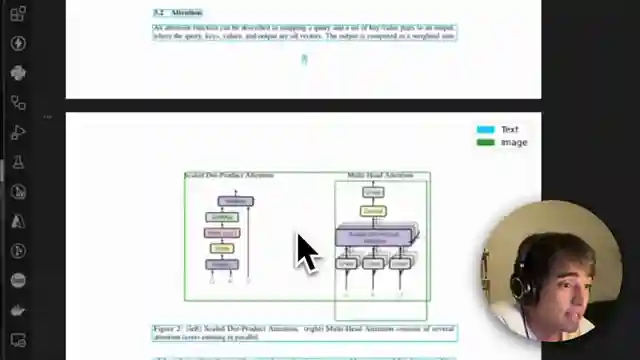
Image copyright Youtube
Image copyright Youtube
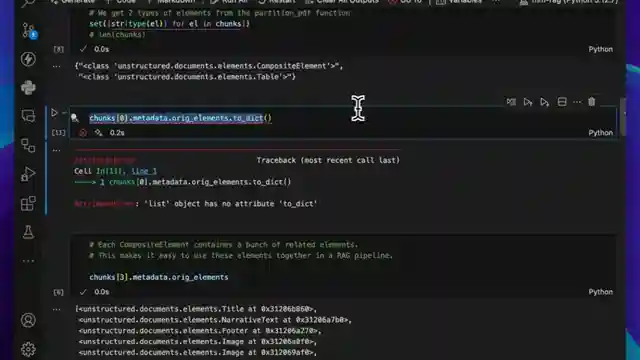
Image copyright Youtube
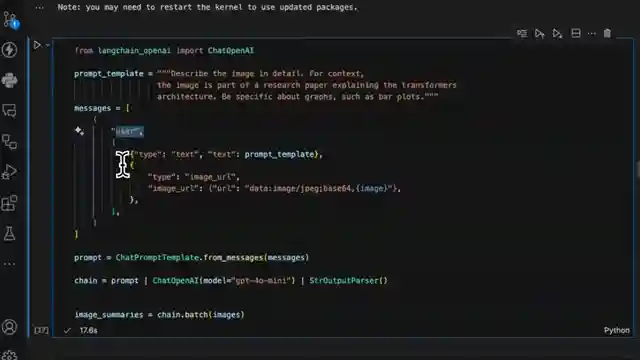
Image copyright Youtube
Watch Multimodal RAG: Chat with PDFs (Images & Tables) [2025] on Youtube
Viewer Reactions for Multimodal RAG: Chat with PDFs (Images & Tables) [2025]
Parsing text_as_html attribute in partition_pdf to extract table content
Appreciation for clear and helpful explanations
Request for tutorial on using local models for sensitive data
Inquiry about alternative open source models to GPT-4 for similar results
Request for video on customer support AI agent
Concerns about library not being suitable for production cases or confidential data
Issue with Rate Limit Error when using retriever.vectorstore.add_documents
Request for langchain documentation link
Overcoming issue with context size exceeding model's limit when passing documents to LLM
Difficulty extracting tables with partition_pdf, similar issues faced by others
Related Articles

Mastering Multi-Agent Systems: AI Research Insights
Discover the power of multi-agent systems in AI research with insights from Anthropic's groundbreaking work. Learn about the benefits, architecture, and prompt engineering strategies for optimizing task performance. Elevate your understanding of token usage, tool calls, and model choice for superior results.

Mastering MCP Server Integration with Cursor: A Step-by-Step Guide
Learn how to create an MCP server and integrate it with Cursor on Alejandro AO - Software & Ai. Develop custom tools for Confluence, enabling precise project information retrieval. Follow the step-by-step guide for setting up and debugging the server securely.

Lama Extract: Automating Structured Data Extraction for PDFs and Images
Lama Extract, a tool by Lama Index, automates structured data extraction from unstructured files like PDFs and images, simplifying the process with defined schemas and a user-friendly interface. Advanced features include batch extraction, schema updates, and custom configurations for efficient data extraction.

Mastering AI Coding: Crafting Effective Prompts for Robust Applications
Learn how to prompt AI coding assistants effectively to create robust applications without technical debt. Understand language models, clear prompts, and examples for efficient coding with AI tools like Cursor and Trey. Master the art of crafting precise instructions for optimal results in coding tasks.