Mastering Deep Reinforcement Learning with Proximal Policy Optimization

- Authors
- Published on
- Published on
Today on Arxiv Insights, the team takes us on a thrilling ride into the world of Proximal Policy Optimization (PPO) by OpenAI. This cutting-edge algorithm is like the James Bond of deep reinforcement learning, tackling tasks from robotic control to dominating video games like Dota 2. Unlike your run-of-the-mill supervised learning, PPO faces the wild west of training data, dynamically shifting with the agent's interactions with the environment. It's a high-stakes game where stability is as elusive as a Yeti in the Himalayas.
PPO, with its swagger and confidence, steps up to the plate to tackle the challenges head-on. It dances in the realm of policy gradient methods, strutting its stuff without the safety net of a replay buffer. The core of PPO's mission lies in balancing simplicity, efficiency, and tuning, making it the Maverick of the deep reinforcement learning world. By incorporating a clever probability ratio and advantage function, PPO navigates the treacherous waters of policy updates with finesse and precision.
The genius of PPO shines through in its optimization objective, a symphony of probability ratios and clipped values that keep policy updates in check. It's like watching a skilled conductor lead an orchestra, ensuring that the performance stays on track without veering off into chaos. PPO's objective function is a work of art, elegantly guiding conservative policy updates that outshine the competition. It's a masterclass in simplicity triumphing over complexity, proving that sometimes, less is truly more in the world of cutting-edge algorithms.

Image copyright Youtube
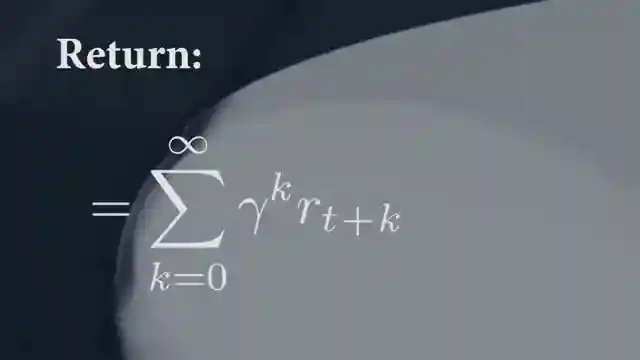
Image copyright Youtube
Image copyright Youtube
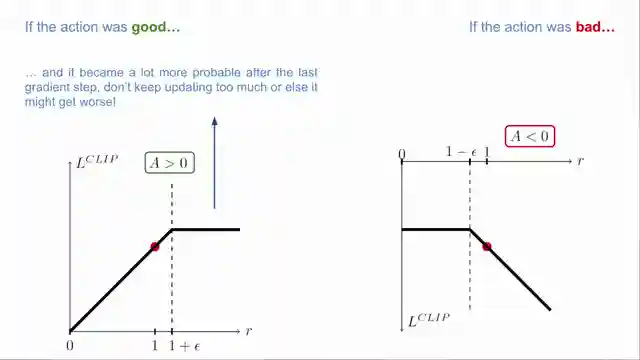
Image copyright Youtube
Watch An introduction to Policy Gradient methods - Deep Reinforcement Learning on Youtube
Viewer Reactions for An introduction to Policy Gradient methods - Deep Reinforcement Learning
Best explanation of PPO on the internet
Video felt shorter than its actual length
Comparison to Siraj Raval
Positive feedback on the RL series
Appreciation for simplifying complex concepts
Request for smaller subscripts/superscripts
Clarification on on-policy and off-policy
Question about using PPO for malware detection
Appreciation for providing additional resources
Request for a continuation of tutorials
Related Articles

Mastering Animation Creation with Texture Flow: A Comprehensive Guide
Discover the intricate world of creating mesmerizing animations with Texture Flow. Explore input settings, denoising steps, and texture image application for stunning visual results. Customize animations with shape controls, audio reactivity, and seamless integration for a truly dynamic workflow.

Unveiling Human Intuition: The Power of Priors in Gaming
Discover how human intuition outshines cutting-edge AI in solving complex environments. Explore the impact of human priors on gameplay efficiency and the limitations of reinforcement learning algorithms. Uncover the intricate balance between innate knowledge and adaptive learning strategies in this insightful study by Arxiv Insights.

Unveiling AlphaGo Zero: Self-Learning AI Dominates Go
Discover the groundbreaking AlphaGo Zero by Google DeepMind, a self-learning AI for Go. Using a residual architecture and Monte Carlo tree search, it outshines predecessors with unparalleled strategy and innovation.
Unveiling Neural Networks: Feature Visualization and Deep Learning Insights
Arxiv Insights delves into interpreting neural networks for critical applications like self-driving cars and healthcare. They explore feature visualization techniques, music recommendation using deep learning, and the Deep Dream project, offering a captivating journey through the intricate world of machine learning.