Llama 4 Benchmark Hacking Scandal: Meta Resignations Unveil Controversy

- Authors
- Published on
- Published on
In this explosive revelation, the Llama 4 launch has been marred by scandalous allegations of benchmark hacking. A Chinese forum post has blown the lid off issues plaguing Llama 4 post-training, leading to a dramatic resignation. The team at 1littlecoder delves deep into the murky waters of artificial analysis, showcasing how Llama 4 stacks up against industry giants like Deepseek V3 and GPT40. While the model appears to shine in certain aspects, concerns loom large over its accuracy in multi-choice questions, casting doubt on its true capabilities.
But hold on tight, because the plot thickens with the unveiling of an experimental version of Llama 4, shrouded in mystery and controversy. The English translation of a damning Chinese post exposes the model's underperformance compared to cutting-edge benchmarks, sparking discussions about the integrity of post-training practices. As the deadline for performance targets looms, resignations from high-ranking Meta officials send shockwaves through the AI community, raising eyebrows and questions about the model's real-world applicability amidst licensing complications.
As enthusiasts and critics alike grapple with the fallout from these bombshell revelations, the future of Llama 4 hangs in the balance. The team at 1littlecoder navigates through the smoke and mirrors of benchmark manipulation, shedding light on a scandal that threatens to rock the foundations of the AI landscape. With Meta's reputation on the line and users questioning the model's efficacy, the stage is set for a showdown of epic proportions. Will Llama 4 emerge victorious, or will it crumble under the weight of its own controversy? Tune in to find out, as the saga of benchmark hacking unfolds in real-time.
Image copyright Youtube
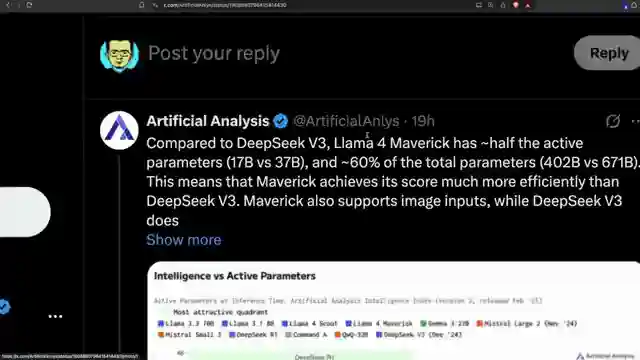
Image copyright Youtube
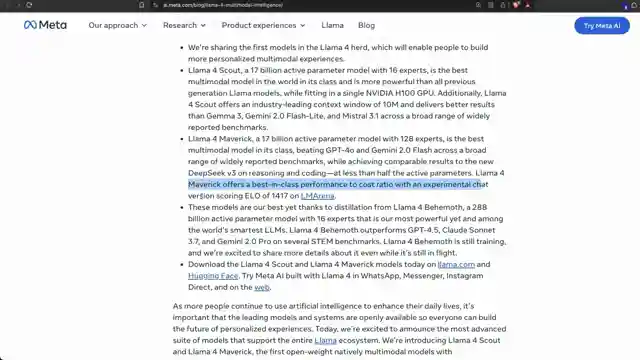
Image copyright Youtube
Image copyright Youtube
Watch Serious Llama 4 Allegations!! on Youtube
Viewer Reactions for Serious Llama 4 Allegations!!
Concerns about the licensing of the models
Speculation about rushed and unoptimized releases
Disappointment with the real-world performance of the model
Comments on the size and practicality of the Llama 4 Scout model
Speculation on Meta's workplace culture
Criticism of the model's performance and quality
Speculation about the training data used for the model
Concerns about the model's ability to generalize
Comments on the competition and expectations from Meta
Speculation about the capabilities of the model on different hardware
Related Articles

Revolutionizing Music Creation: Google's Magenta Real Time Model
Discover Magenta, a cutting-edge music generation model from Google deep mind. With 800 million parameters, Magenta offers real-time music creation on Google Collab TPU. Available on Hugging Face, this AI innovation is revolutionizing music production.

Nanits OCRS Model: Free Optical Character Recognition Tool Outshines Competition
Discover Nanits' OCRS model, a powerful optical character recognition tool fine-tuned from Quinn 2.5 VLM. This free model outshines Mistral AI's paid OCR API, excelling in latex equation recognition, image description, signature detection, and watermark extraction. Accessible via Google Collab, it offers seamless conversion of documents to markdown format. Experience the future of OCR technology with Nanits.

Revolutionizing Voice Technology: Chatterbox by Resemble EI
Resemble EI's Chatterbox, a half-billion parameter model licensed under MIT, excels in text-to-speech and voice cloning. Users can adjust parameters like pace and exaggeration for customized output. The model outperforms competitors, making it ideal for diverse voice applications. Subscribe to 1littlecoder for more insights.

Unlock Productivity: Google AI Studio's Branching Feature Revealed
Discover the hidden Google AI studio feature called branching on 1littlecoder. This revolutionary tool allows users to create different conversation timelines, boosting productivity and enabling flexible communication. Branching is a game-changer for saving time and enhancing learning experiences.