Exploring OpenAI's GPT 4.5: Performance, Costs, and Future Prospects

- Authors
- Published on
- Published on
In this riveting episode of AI Explained, we delve into the world of GPT 4.5, the latest brainchild from the folks at OpenAI. This behemoth of a language model comes with a hefty price tag, catering exclusively to pro users at a steep $200 tier. But does it deliver the goods? Well, let's just say it's a bit like bringing a bazooka to a knife fight. GPT 4.5 falls short in scientific and mathematical benchmarks, leaving much to be desired in terms of raw performance. It's like showing up at a drag race with a lawnmower engine - disappointing, to say the least.
Despite its shortcomings, GPT 4.5 aims to up its game in the emotional intelligence department. But when put to the test in scenarios like detecting spousal abuse through humor, the results are, well, a bit cringeworthy. It's like watching a toddler try to perform brain surgery - you just hope for the best but expect a disaster. On the creative writing front, GPT 4.5 struggles to show, not tell, unlike its counterpart Claude 3.7, who paints vivid pictures with words. It's like comparing a Picasso to a paint-by-numbers kit - one's art, the other's just coloring.
Now, when it comes to humor, GPT 4.5 falls flat on its face, lacking the finesse and wit of Claude 3.7. It's like watching a stand-up comedian bomb on stage - awkward and uncomfortable. And let's not forget the elephant in the room - the eye-watering cost of GPT 4.5. At 15 to 30 times the price of its predecessor, GPT 40, you'd expect it to churn out Shakespearean masterpieces on demand. But alas, the reality falls short of the hype. However, there's a glimmer of hope in the incremental improvements seen in base models like GPT 4.5, hinting at a brighter future for AI reasoning models. It's like witnessing the evolution of a hatchling into a full-fledged dragon - exciting, unpredictable, and full of potential.
Image copyright Youtube

Image copyright Youtube

Image copyright Youtube
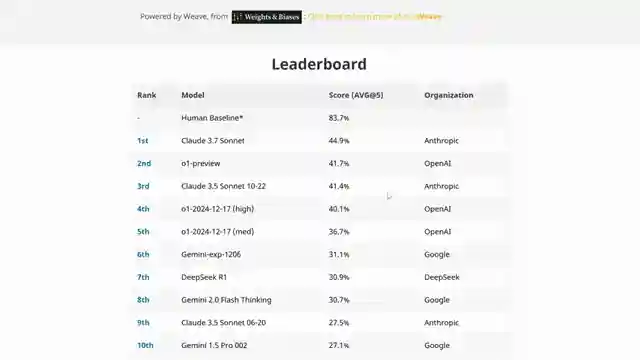
Image copyright Youtube
Watch GPT 4.5 - not so much wow on Youtube
Viewer Reactions for GPT 4.5 - not so much wow
Bob tweet summarized as spot on TLDR for model performance
Claude's ability to detect testing is impressive
Discussion on GPT-4.5 not crushing benchmarks but creating hype for AGI
Comparison of EQ between ChatGPT 4.5 and Claude
Mention of Anthropic getting free promo from 4.5 release
Views on Claude's EQ and personality over intelligence
Comparison of GPT-4.5 and Claude 3.7
Speculation on future AI developments and competitiveness
Excitement for Claude 3.7 and potential comparisons with other models
Criticism of OpenAI's efficiency and innovation compared to other labs
Related Articles

AI Limitations Unveiled: Apple Paper Analysis & Model Recommendations
AI Explained dissects the Apple paper revealing AI models' limitations in reasoning and computation. They caution against relying solely on benchmarks and recommend Google's Gemini 2.5 Pro for free model usage. The team also highlights the importance of considering performance in specific use cases and shares insights on a sponsorship collaboration with Storyblocks for enhanced production quality.

Google's Gemini 2.5 Pro: AI Dominance and Job Market Impact
Google's Gemini 2.5 Pro dominates AI benchmarks, surpassing competitors like Claude Opus 4. CEOs predict no AGI before 2030. Job market impact and AI automation explored. Emergent Mind tool revolutionizes AI models. AI's role in white-collar job future analyzed.

Revolutionizing Code Optimization: The Future with Alpha Evolve
Discover the groundbreaking Alpha Evolve from Google Deepmind, a coding agent revolutionizing code optimization. From state-of-the-art programs to data center efficiency, explore the future of AI innovation with Alpha Evolve.

Google's Latest AI Breakthroughs: V3, Gemini 2.5, and Beyond
Google's latest AI breakthroughs, from V3 with sound in videos to Gemini 2.5 Flash update, Gemini Live, and the Gemini diffusion model, showcase their dominance in the field. Additional features like AI mode, Jewels for coding, and the Imagine 4 text-to-image model further solidify Google's position as an AI powerhouse. The Synth ID detector, Gemmaverse models, and SGMema for sign language translation add depth to their impressive lineup. Stay tuned for the future of AI innovation!