Decoding OpenAI's 04 Mini vs 03 Models: Hype, Flaws & Progress

- Authors
- Published on
- Published on
In this thrilling episode of AI Explained, the team delves into the latest buzz surrounding OpenAI's 04 Mini and 03 models. Buckle up, folks, as they question the validity of the hype, hinting at potential favoritism in early access distribution. While acknowledging the models' advancements over their predecessors, they slam on the brakes, doubting claims of surpassing genius levels. Revving up their argument with hard evidence from multiple tests, they take these AI wonders for a spin, revealing flaws and errors that put a dent in the AGI dream.
Comparing these cutting-edge models to the likes of Gemini 2.5 Pro and Anthropics Claude 3.7, the team shifts into high gear, casting doubt on the AGI status bestowed upon 03. Despite impressive showings in benchmark tests like competitive mathematics and coding, they slam the brakes on the notion of hallucination-free AI, pointing out major errors that rear their ugly heads. They navigate the winding roads of pricing discrepancies between 03 and Gemini 2.5 Pro, highlighting performance disparities and cost-effectiveness concerns that steer the conversation in a different direction.
Zooming into the models' capabilities, from handling YouTube videos to dissecting metadata with surgical precision, the team peels back the layers of AI sophistication. With a pit stop to discuss training data limits, release notes, and external evaluations, they shift gears, urging viewers to test these AI beasts across various domains to truly gauge their horsepower. With a final lap around the track, they hint at the future of AI performance and scalability, signaling a thrilling race ahead where progress trumps sensational headlines.
Image copyright Youtube

Image copyright Youtube
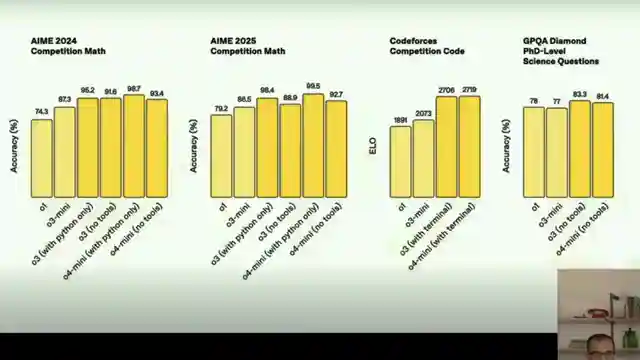
Image copyright Youtube
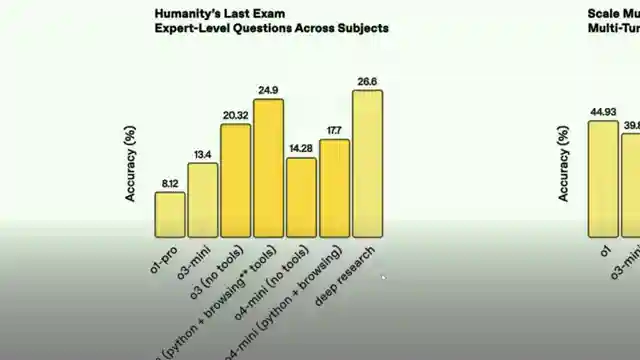
Image copyright Youtube
Watch o3 and o4-mini - they’re great, but easy to over-hype on Youtube
Viewer Reactions for o3 and o4-mini - they’re great, but easy to over-hype
Frequency of video uploads
Comparison between London and San Francisco cultures
Spatial reasoning in models
Performance on benchmarks as a measure of AGI
Early access and hyping up models
Tool use for o3 and o4 mini
Cost comparison between o3 and o1-pro
Concerns about LLMs being a dead end
Gemini 2.5 Pro and potential for o4.1
Benchmark-maximizer as a term and its implications for AI development
Related Articles

AI Limitations Unveiled: Apple Paper Analysis & Model Recommendations
AI Explained dissects the Apple paper revealing AI models' limitations in reasoning and computation. They caution against relying solely on benchmarks and recommend Google's Gemini 2.5 Pro for free model usage. The team also highlights the importance of considering performance in specific use cases and shares insights on a sponsorship collaboration with Storyblocks for enhanced production quality.

Google's Gemini 2.5 Pro: AI Dominance and Job Market Impact
Google's Gemini 2.5 Pro dominates AI benchmarks, surpassing competitors like Claude Opus 4. CEOs predict no AGI before 2030. Job market impact and AI automation explored. Emergent Mind tool revolutionizes AI models. AI's role in white-collar job future analyzed.

Revolutionizing Code Optimization: The Future with Alpha Evolve
Discover the groundbreaking Alpha Evolve from Google Deepmind, a coding agent revolutionizing code optimization. From state-of-the-art programs to data center efficiency, explore the future of AI innovation with Alpha Evolve.

Google's Latest AI Breakthroughs: V3, Gemini 2.5, and Beyond
Google's latest AI breakthroughs, from V3 with sound in videos to Gemini 2.5 Flash update, Gemini Live, and the Gemini diffusion model, showcase their dominance in the field. Additional features like AI mode, Jewels for coding, and the Imagine 4 text-to-image model further solidify Google's position as an AI powerhouse. The Synth ID detector, Gemmaverse models, and SGMema for sign language translation add depth to their impressive lineup. Stay tuned for the future of AI innovation!